Backlog API | データをダッシュボードで可視化する方法を解説!

▼データマーケティングの教科書 下

初心者の方から、より詳しくなりたいという方へ。
本書ではデータマーケティングの基礎から学び、データを通じて顧客の行動や感情を理解し、
より確かな意思決定を目指します。
みなさん、こんにちは!
突然ですが、Backlogというツールを使ったことはありますか?
タスク管理や課題管理のツールとして、チームでのやり取りに活用している方も多いのではないでしょうか。
実はこのBacklog、画面上で操作するだけでなく、外部から情報を取得したり、更新したりできる仕組みも用意されています。
それが 「Backlog API」 です。
本記事では、Backlog APIの基本的な使い方から、Looker Studioと連携して、タスク内容を可視化する方法までを、初心者の方にもイメージしやすいよう、できるだけわかりやすくご紹介します。
「APIはちょっと難しそう…」と感じている方でも、何ができて、どんな場面で使えるのかが伝わる内容になっていますので、ぜひ最後まで読んでみてください。
目次
Backlogとは?
Backlogは、タスク管理・課題管理を中心としたプロジェクト管理ツールです。チーム内の作業を「課題」として登録し、担当者・期限・進捗状況を一元管理できます。
たとえば、
・誰が、何を担当しているのか
・今どの作業が進行中なのか
・期限が近いタスクはどれか
といった情報を一覧で把握できるのが特徴です。
主な機能として下記のようなものがあります。
課題登録機能
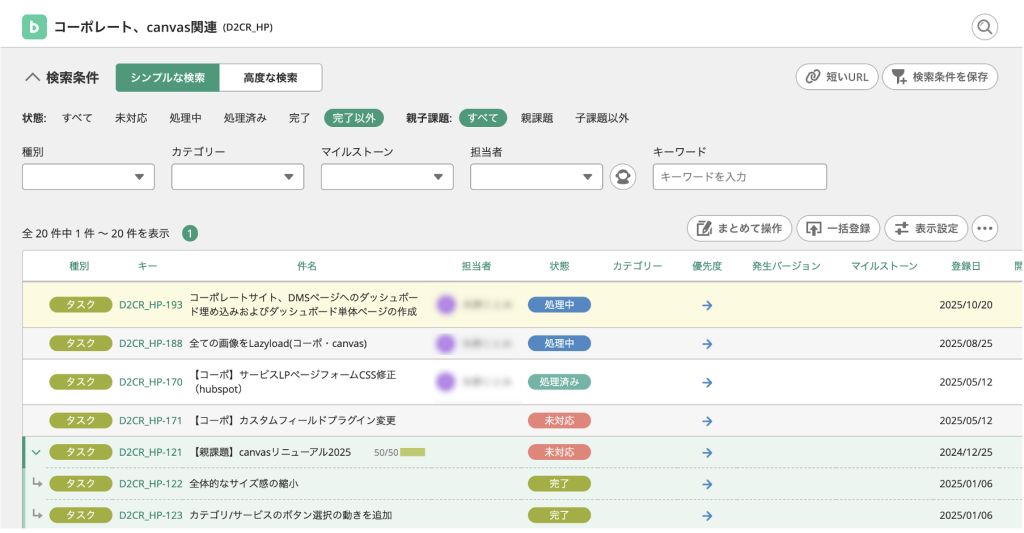 Backlogの課題登録機能は、日々の業務やプロジェクトで発生する作業を一つひとつ「課題」として登録し、管理するための基本機能です。課題には件名や詳細内容だけでなく、担当者や期限日、優先度、進捗状態などを設定できるため、「誰が」「いつまでに」「何をするのか」を明確にすることができます。
Backlogの課題登録機能は、日々の業務やプロジェクトで発生する作業を一つひとつ「課題」として登録し、管理するための基本機能です。課題には件名や詳細内容だけでなく、担当者や期限日、優先度、進捗状態などを設定できるため、「誰が」「いつまでに」「何をするのか」を明確にすることができます。
これにより、口頭やチャットだけでは抜け漏れが発生しがちなタスクも、Backlog上で確実に把握できるようになります。
ガントチャート機能
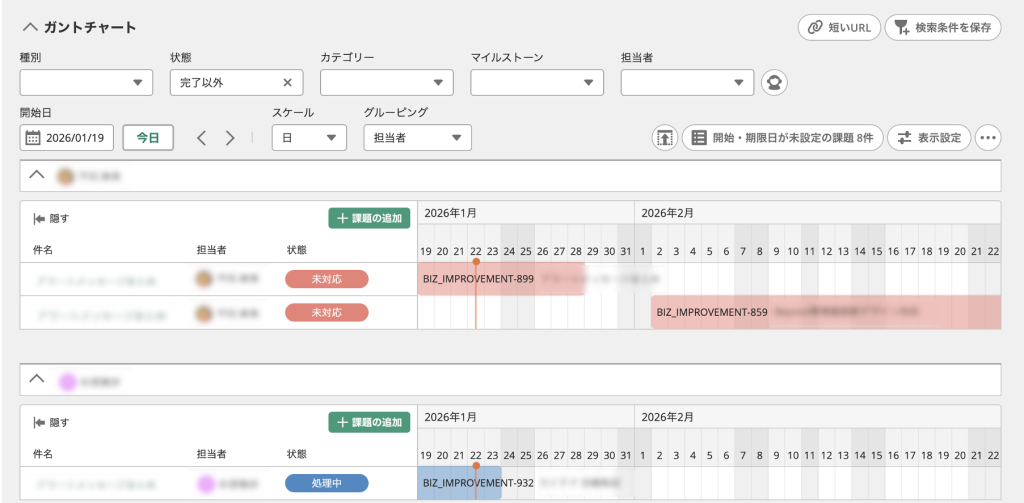 ガントチャート機能は、Backlogに登録された課題を時間軸に沿って可視化し、プロジェクト全体のスケジュールを把握するための機能です。課題に設定された開始日と期限日をもとに、各作業が棒グラフとして表示されるため、どの作業がいつ行われ、どのタイミングで重なっているのかを一目で確認できます。
ガントチャート機能は、Backlogに登録された課題を時間軸に沿って可視化し、プロジェクト全体のスケジュールを把握するための機能です。課題に設定された開始日と期限日をもとに、各作業が棒グラフとして表示されるため、どの作業がいつ行われ、どのタイミングで重なっているのかを一目で確認できます。
これにより、作業の遅れやスケジュールの偏りを早期に発見しやすくなり、計画の見直しや調整を行う判断材料として活用できます。
コメント機能
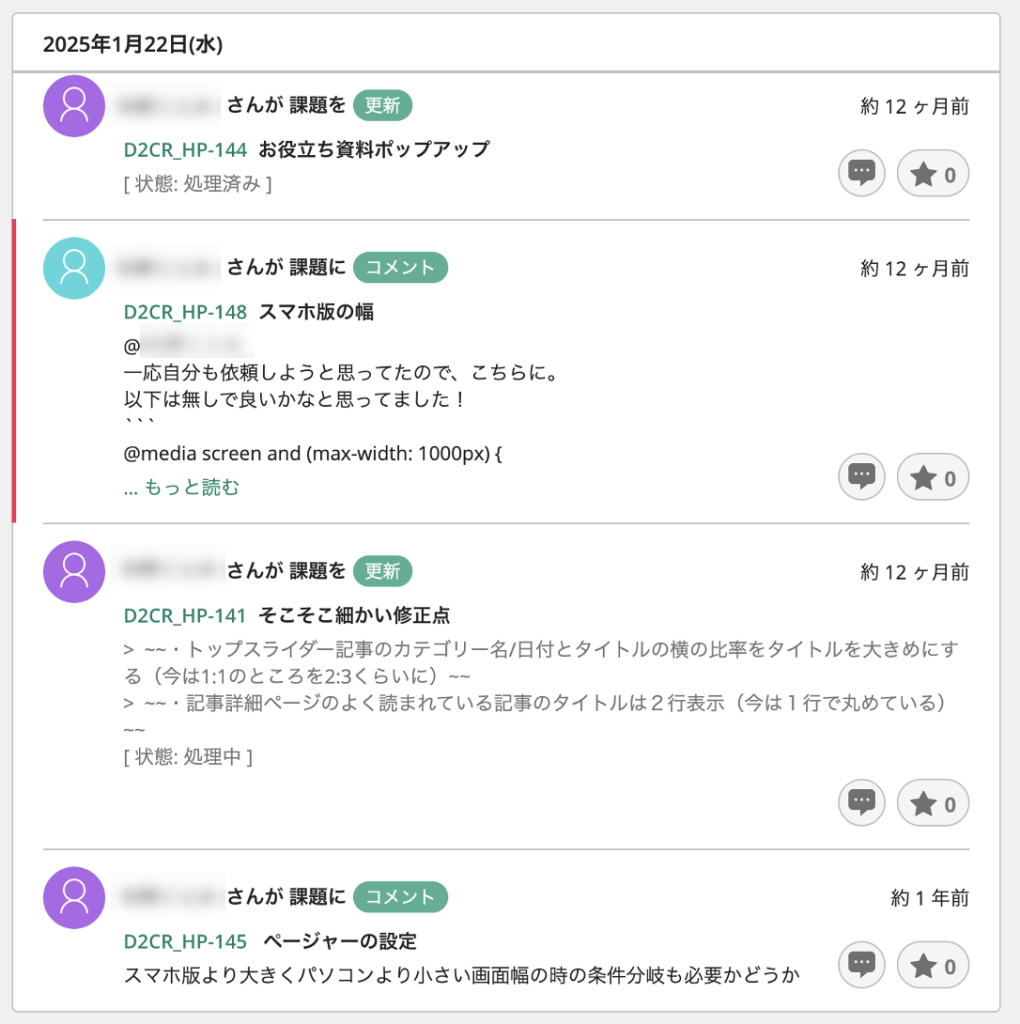
Backlogのコメント機能は、各課題に紐づけてやり取りを行い、コミュニケーションの履歴を残すための機能です。課題に関する質問や進捗報告、相談内容をコメントとして記録できるため、やり取りが他のツールに分散することなく、一か所に集約されます。また、ファイルを添付したり、特定のメンバーにメンションを付けて通知したりすることも可能です。
これにより、過去の経緯や判断理由を後から振り返りやすくなり、引き継ぎや認識合わせもスムーズに行えます。
Backlogには、これまでに紹介した課題登録、ガントチャート、コメント機能のほかにも、プロジェクト運営を支援するさまざまな機能が用意されています。
例えば、プロジェクト全体の情報を共有するためのWiki機能、ファイルを一元管理するためのファイル管理機能、ソースコードを管理するためのGit機能などがあり、業務の背景や経緯を含めてチームで共有しやすい環境を構築できます。
Backlog APIってなに?
Backlog APIは、Backlogのデータを外部から操作するためのインターフェースです。 ブラウザ上で人が行っている操作を、HTTPリクエストを通じてプログラムから実行できるようになります。
Backlogに登録されている「課題・コメント・プロジェクト・ユーザー」などの情報を、取得・作成・更新できるのが特徴です。
Backlog APIでできること
Backlog APIでは、Backlogにある各種リソースに対して操作を行えます。
取得(GET)
・課題一覧
・課題詳細
・課題に紐づくコメント
・プロジェクト情報
・ユーザー情報
登録・更新(POST / PUT)
・課題の新規作成
・課題の状態
・担当者
・期限の更新
・コメントの追加
これらの操作を、画面操作なしで実行できます。
どういうときに使う?
Backlog APIは、Backlogの情報を他のシステムで活用したいときに使われます。
・Backlogの課題データをスプレッドシートに連携したい
・プロジェクトの進捗を自動で集計したい
・課題の更新をトリガーに、別の処理を動かしたい
単なる「自動操作」ではなく、Backlogを業務データの提供元として使うイメージです。
Backlog APIを使ってみよう
事前準備
Backlog APIを利用するためには、まずAPIキーを発行します。APIキーは、Backlog上で操作を行うユーザーを識別するための認証情報です。
APIキーはパスワードと同じ役割を持つため、外部に公開しないよう注意が必要です。
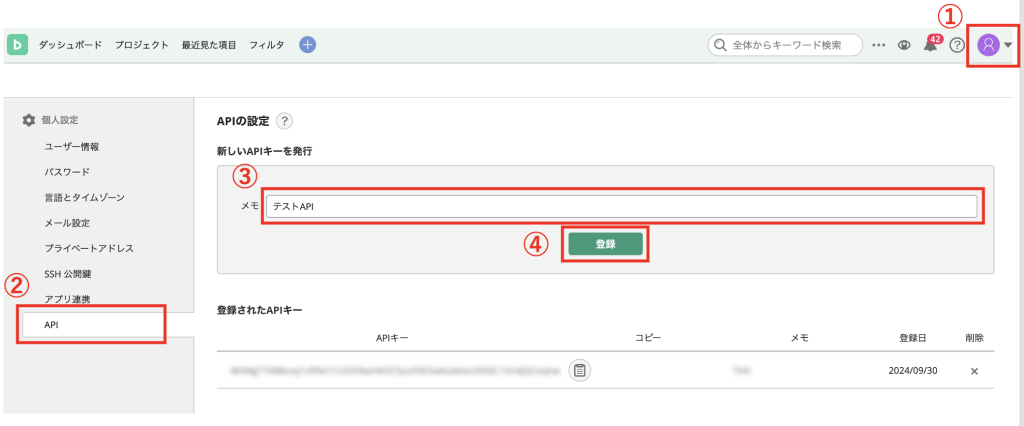 ①右上のアイコンから「個人設定」を開く。
①右上のアイコンから「個人設定」を開く。
②左のサイドバーから「API」を選択。
③必要であればメモを記載。
④「登録」をクリック。  新しいAPIキーが追加されたことがわかります。
新しいAPIキーが追加されたことがわかります。
課題一覧を取得してみよう
今回は一番基本的な、ブラウザにURLを貼って課題一覧を取得する方法をご紹介します。
URLの作成
URL https://{{YOUR-DOMAIN}}/api/v2/issues?apiKey=$API_KEY
・{{YOUR-DOMAIN}}には対象のスペースのドメインを記入。
・$API_KEYには先ほど登録したAPIキーを記入。
🔎 ドメインについて
{{YOUR-DOMAIN}}とは、BacklogのURLです。下記のいずれかになります。
https:// [スペースID] .backlog.jp
https:// [スペースID] .backlog.com
https://[スペースID].backlogtool.com
条件の指定
条件を絞って課題を取得したい場合、URLにパラメータを付ける必要があります。
プロジェクトを指定 ?projectId[]=XXXXX
ステータスを指定&statusId[]=X
URLの完成形https://{{YOUR-DOMAIN}}/api/v2/issues?projectId[]=XXXXX&statusId[]=X&apiKey=$API_KEY
他にも様々な条件指定ができるので、詳しく知りたい方はこちらをご覧ください。 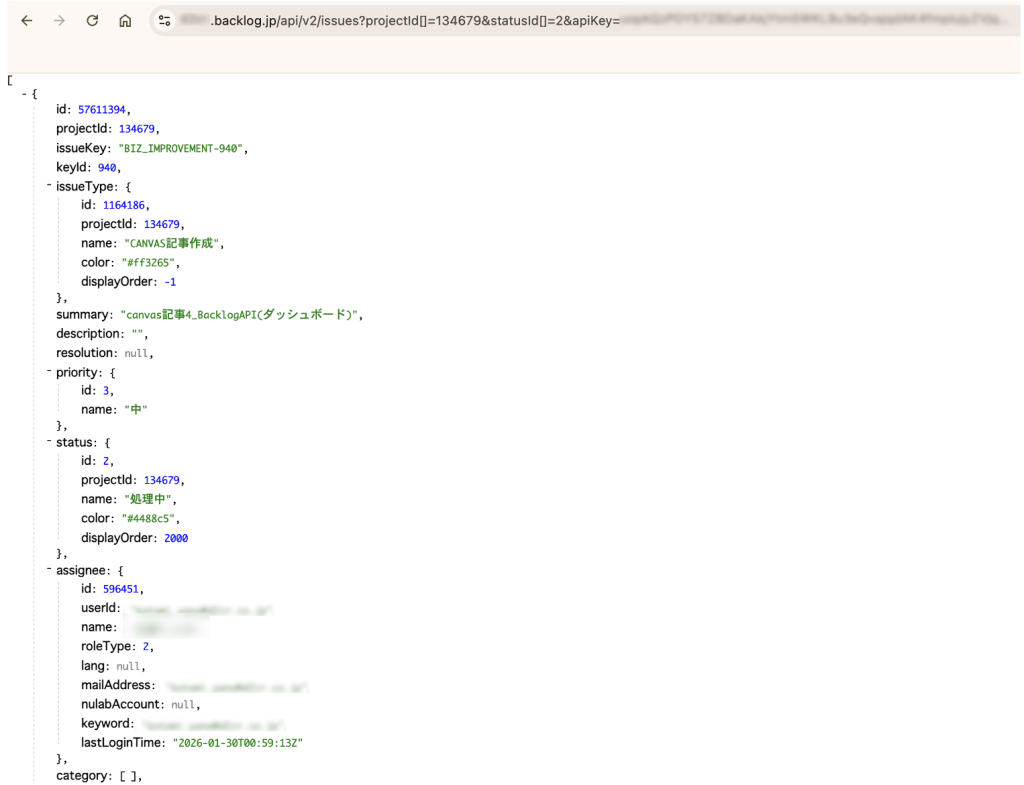 URLをブラウザに貼ると、このようなJSON形式のデータが返ってきます。
URLをブラウザに貼ると、このようなJSON形式のデータが返ってきます。
Backlog API × Looker Studio
次に、Backlogのデータを集計し、Looker Studioで可視化する仕組みをご紹介します。
全体の流れ

Backlog(API)
Backlog APIについては、先ほどご紹介した方法で取得します。
Cloud Run functions でデータ取得
今回は、Cloud Run functionsを使って、Backlog APIを定期的に呼び出して課題データを取得し、BigQueryに保存する処理を行います。
🔎 Cloud Run functionsとは?
Google Cloudが提供するサーバーレスな実行環境です。
・イベント駆動:HTTPリクエストやファイルの保存などを「きっかけ」に、特定のコードを自動実行します。
・運用いらず:サーバーの管理・構築が不要で、処理量に合わせて勝手に拡張(スケーリング)します。
・コスト最適化:コードが動いている時間だけ課金されるため、APIや定期バッチに最適です。
Cloud Source Repositoriesでコードを管理
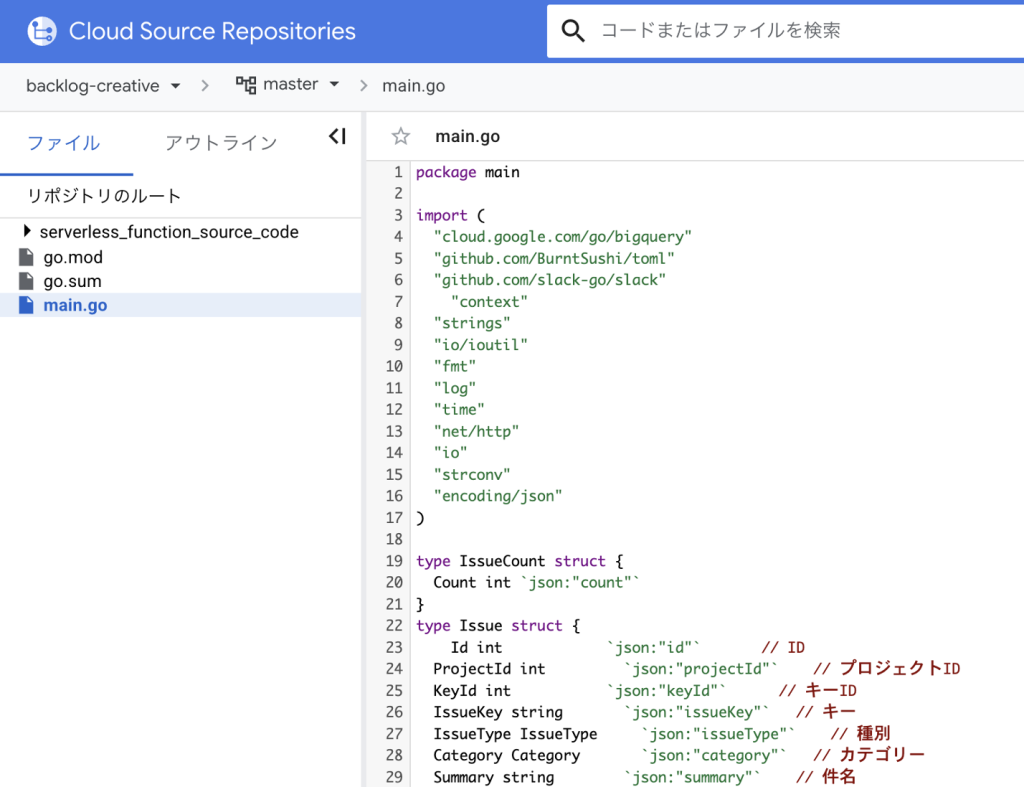 Cloud Run Functions は、Cloud Source Repositories に置かれたコードをもとに処理を実行します。Backlog APIを使って行われるデータ取得や整形のロジックは、このリポジトリ内のコードとして管理されています。
Cloud Run Functions は、Cloud Source Repositories に置かれたコードをもとに処理を実行します。Backlog APIを使って行われるデータ取得や整形のロジックは、このリポジトリ内のコードとして管理されています。
Backlogからデータを取ってくる
for i := 0; i < loopCount; i++ {
offset := strconv.Itoa(100*i)
url = confBacklog.Url + "issues?projectId[]=" + confBacklog.ProjectId + "&count=100&offset=" + offset + "&apiKey=" + confBacklog.APIKey
body, err = getApi(url)
...
// API実行
func getApi(url string) ([]byte, error) {
resp, err := http.Get(url)
if err != nil {
return nil, err
}
defer resp.Body.Close()
if resp.StatusCode != 200 {
return nil, fmt.Errorf("Response Error: %v", resp.Status)
}
return io.ReadAll(resp.Body)
}
BacklogのAPIを叩いて、プロジェクト内の全課題を取得します。1回で全部取ると重いため、「100件ずつ」に分けて、何度も繰り返し取得。
データの加工
for _, v1 := range issues { customFields1 := v1.CustomFields for _, v2 := range customFields1 { var existsColumn bool id1 := v2.Id value1 := v2.Value // 依頼元部署 if id1 == confCustomFields.Department { department, existsColumn = getInterfaceValMap(value1) } // ラフ/素材 ステータス if id1 == confCustomFields.MaterialStatus { materialStatus, existsColumn = getInterfaceValMap(value1) } // 案件名 if id1 == confCustomFields.ProjectTitle { projectTitle, existsColumn = getInterfaceValString(value1) }
Backlog特有の項目を1つずつ変数に代入し、取得した複雑なデータをデータベースに入る形に整えます。
BigQueryにデータを保存
QUERY = "INSERT INTO " + creativeTable + " values" + insertValue
q := client.Query(QUERY)
_, err = q.Read(ctx)整形した大量のデータを、このステップで一気にBigQueryへ書き込みます。
⏰ Cloud Scheduler で自動実行
Cloud Schedulerに実行のスケジュールを設定し、決まった時間にBacklogからのデータ取得→BigQueryへのデータ保存の処理を行っています。
BigQueryに蓄積
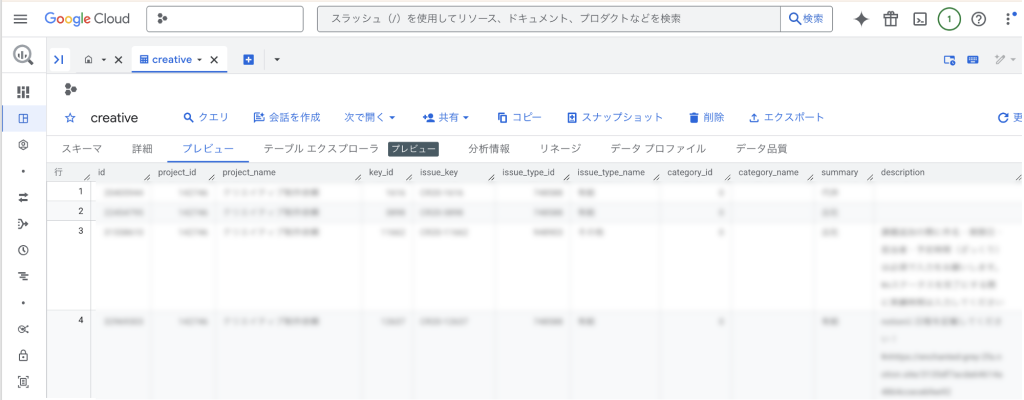 取得してきた課題データがBigQueryのテーブルに蓄積されます。
取得してきた課題データがBigQueryのテーブルに蓄積されます。
Looker Studioでデータの可視化
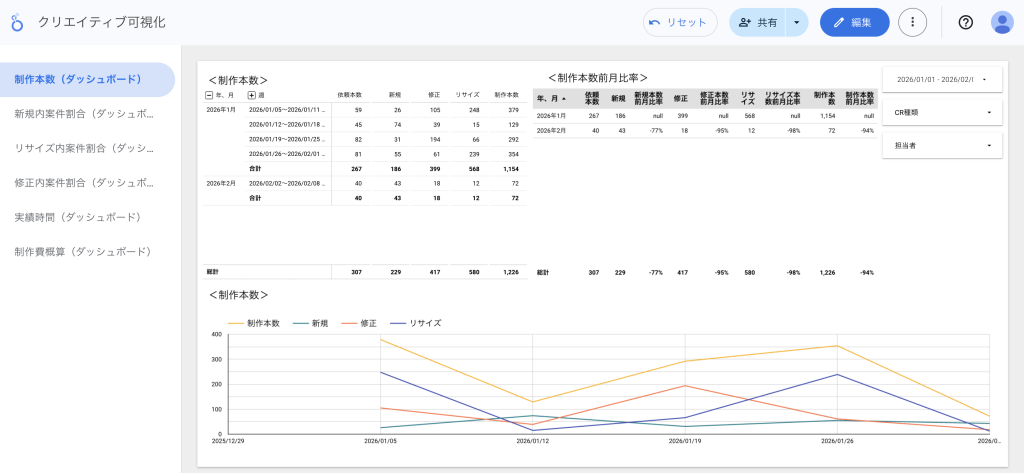 データソースを登録することで、前のステップでBigQueryが更新されていれば、最新のデータが画面上のグラフに反映されます。
データソースを登録することで、前のステップでBigQueryが更新されていれば、最新のデータが画面上のグラフに反映されます。
データソースの追加
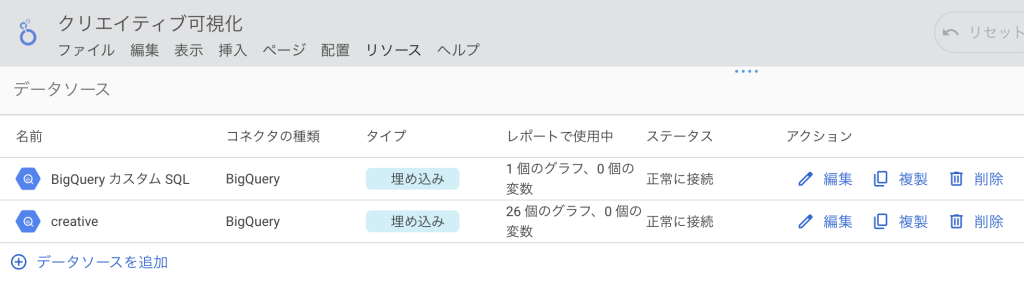
今回のレポートでは、可視化するデータに合わせて2種類の接続方法を使い分けています。
① カスタムクエリ
目的:「前月比」などの計算が必要なグラフ。
特徴:SQLを用いて「先月の数値と比較する」といった計算を行っています。
② テーブル直接連携
目的:制作本数や案件名・案件数、担当者のリストなど。
特徴:BigQuery内のデータをそのまま表示するのに適しています。
完成
⬇︎
1. データ取得と書き込み(Cloud Run Functions)
Go言語で記述されたプログラムが起動し、以下の処理を順次実行します。
抽出: Backlog APIを介して、100件ずつのページネーション処理を行いながら全課題データを取得。
変換:APIから取得したJSONデータを、BigQueryのスキーマに適合するようデータ型や文字列を整形。
書き込み:最新データをINSERT文によってBigQueryへ挿入。
⏰ 実行トリガー(Cloud Scheduler)
指定されたスケジュールに基づき、Cloud Run Functionsを起動。
2. データ蓄積(BigQuery)
テーブルにすべての課題データを構造化データとして保存。
3. レポート表示(Looker Studio)
BigQueryから返却された集計結果を、設定された日付や指標(件数等)に基づきグラフや表として描画。
まとめ
Backlog APIを使うことで、Backlog上の課題データを外部から取得し、集計・分析に活用できます。 本記事では、APIキーの発行から課題一覧の取得方法まで、基本的な使い方を初心者向けに解説しました。
さらにCloud Run FunctionsとBigQueryを組み合わせることで、課題データを定期的に自動取得・保存し、Looker Studioで可視化できる仕組みも紹介しました。
この仕組みを構築することで、Backlogを開かなくてもチームの課題状況をダッシュボードで把握できるようになります。
Backlogの社内活用や、BigQuery・Looker Studioを使った業務効率化に興味がある方は、こちらよりお気軽にお問い合わせください。
▼Looker Studioについて詳しく知りたい方
Looker Studioとは?主要機能・活用事例をご紹介!
Looker Studioデータの接続・統合手順を解説!
Looker Studioでグラフの追加&カスタマイズのポイントを紹介!
チームで使うLooker Studio|権限の種類・定期配信など共有設定を徹底解説!
この記事が参考になった方は「いいね」やシェアをお願いします!
▼データマーケティングの教科書 下
初心者の方から、より詳しくなりたいという方へ。
本書ではデータマーケティングの基礎から学び、データを通じて顧客の行動や感情を理解し、
より確かな意思決定を目指します。
編集者
エンジニアチーム
編集者
エンジニアチーム
GASやLooker Studio、TROCCOなどのツールを活用した、業務効率化やデータ活用のノウハウをわかりやすく発信しています!



