Looker Studioデータの接続・統合手順を解説!

▼データマーケティングの教科書 下

初心者の方から、より詳しくなりたいという方へ。
本書ではデータマーケティングの基礎から学び、データを通じて顧客の行動や感情を理解し、
より確かな意思決定を目指します。
みなさん、こんにちは。
前回Looker Studioの主要機能や活用事例をご紹介しましたが、効果的に活用するための第一歩はデータの接続と統合です。
本記事では、Looker Studioへのデータ接続手順に加え、カスタムクエリを用いた柔軟なデータ抽出方法や、複数テーブルの結合方法についてもご紹介します。
初めてLooker Studioを使う方はもちろん、すでに使い始めているけれどデータの扱いに幅を持たせたい方にも役立つ内容となっています。ぜひ最後までご覧いただき、日々のデータ活用にお役立てください!
目次
データの追加手順
Looker StudioはGoogle Analytics、スプレッドシート、BigQueryなどのGoogle関連サービスをはじめ、Facebook広告(Meta広告)、Yahoo!広告など、800種類以上のデータソースと連携することができます。
(※Looker Studio上のデータソース名のため媒体の正式名称と異なる場合があります)
ヘッダーから「データを追加」
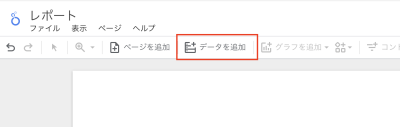
接続したいデータソースを選択
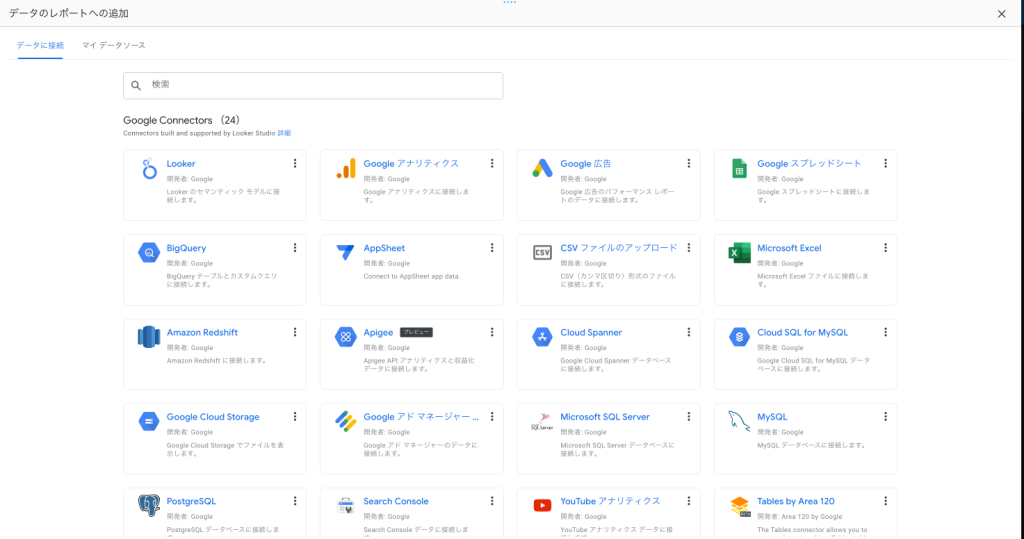
BigQueryを選択した場合
プロジェクトからデータセット>テーブルを選択する方法とカスタムクエリを入力する方法があります。
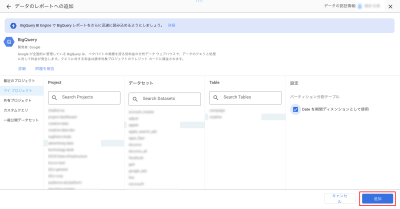
カスタムクエリを使用する場合は、プロジェクトを選択し、クエリエディタにSQLクエリを記述することでLooker Studioに取り込む前にデータ抽出や操作を定義することができます。
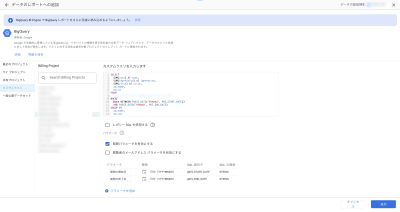
またカスタムクエリでは「期間パラメーターを有効にする」ことができます。
レポートに期間設定が含まれる場合、閲覧者はその期間設定を使用して異なる開始日および終了日のデータをリクエストできます。
SELECT creation_date,age, display_name from user.users as user
WHERE creation_date > PARSE_DATE('%Y%m%d', @DS_START_DATE)
AND creation_date < PARSE_DATE('%Y%m%d', @DS_END_DATE);
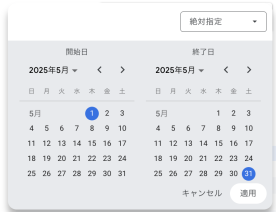
閲覧者が選択した2025/05/01から2025/05/31のデータが表示されます
また期間パラメータだけでなく、カスタムクエリ本文でハードコードされた@で始まる識別子をパラメータとして使用することができます。
SELECT word FROM `TABLE` WHERE corpus = @corpus;
| パラメータ | 目的 |
| @DS_START_DATE | レポート期間の開始日 |
| @DS_END_DATE | レポート期間の終了日 |
| @DS_USER_EMAIL | ログイン ユーザーのメールアドレス |
パラメータを活用することで、カスタムクエリの結果を動的に変更でき、より柔軟でカスタマイズ性の高いレポートを作成できます。
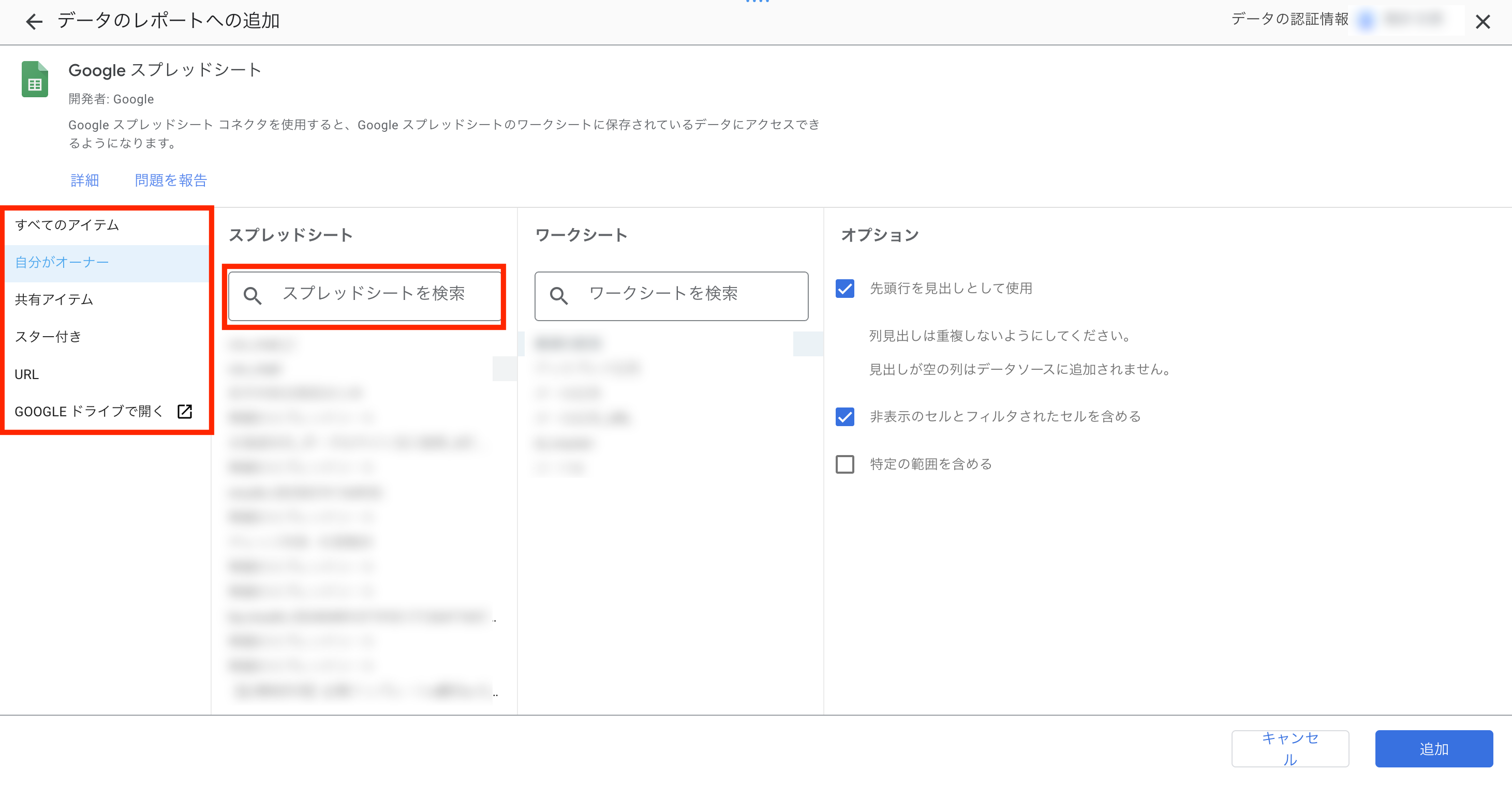
Googleスプレッドシートを選択した場合
検索やURLからスプレッドシートを選択します。
先頭行を見出しとして使用したり、特定の範囲のみ取り込みが可能です。
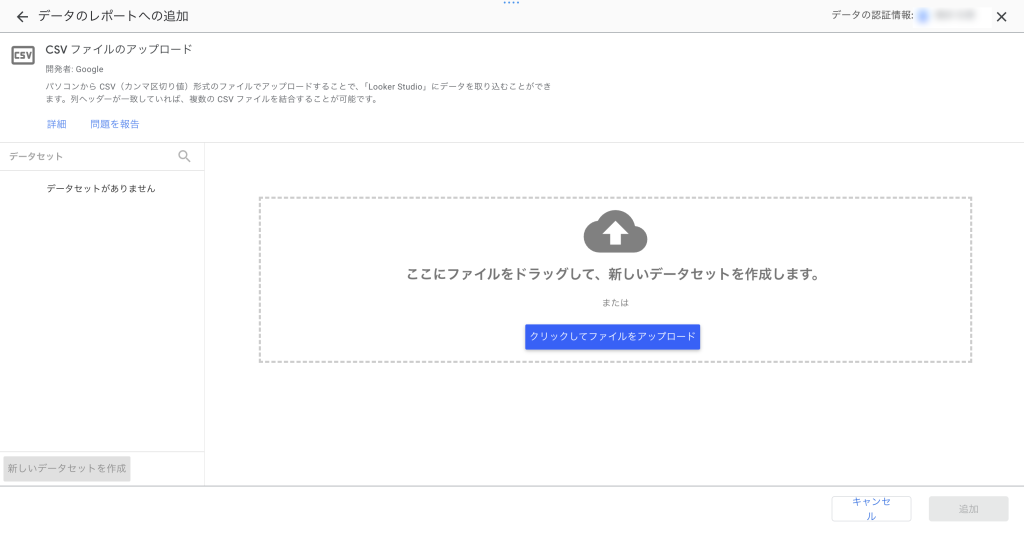
CSVファイルを選択した場合
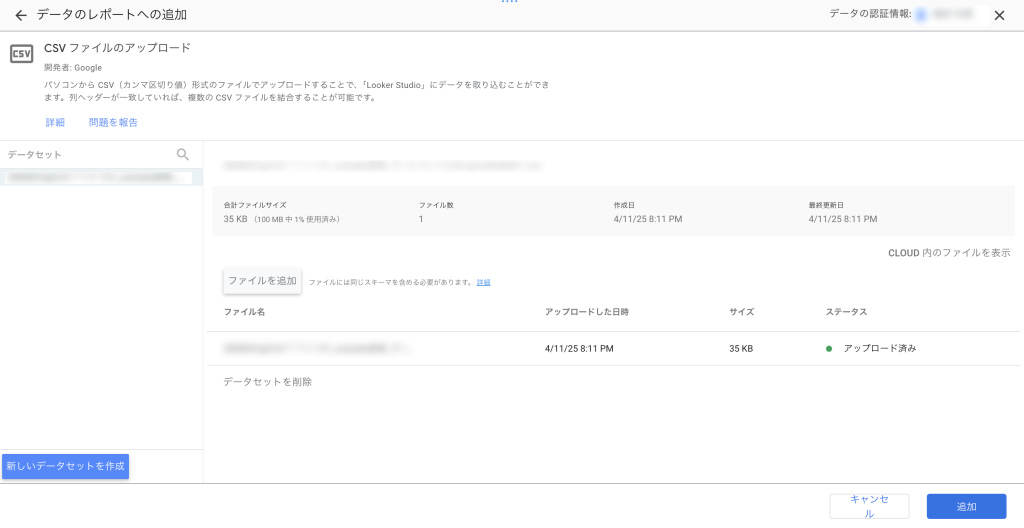
CSVファイルは、ドラッグ&ドロップ、またはクリックして選択することでアップロードできます。列ヘッダーが一致している場合は、複数のCSVファイルを自動的に結合することが可能です。
データの認証情報を設定する
「データの認証情報」からデータにアクセスできるユーザーを選択します。
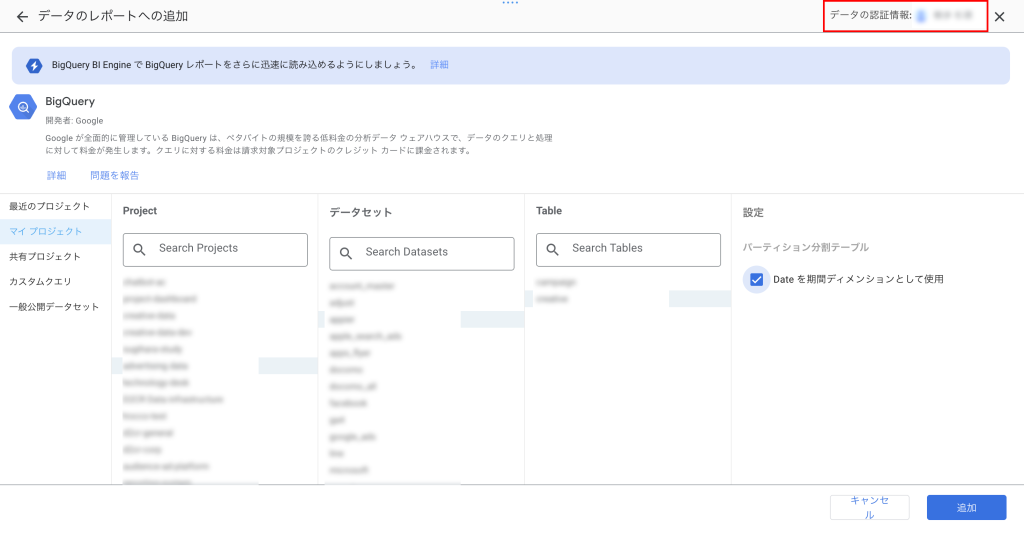
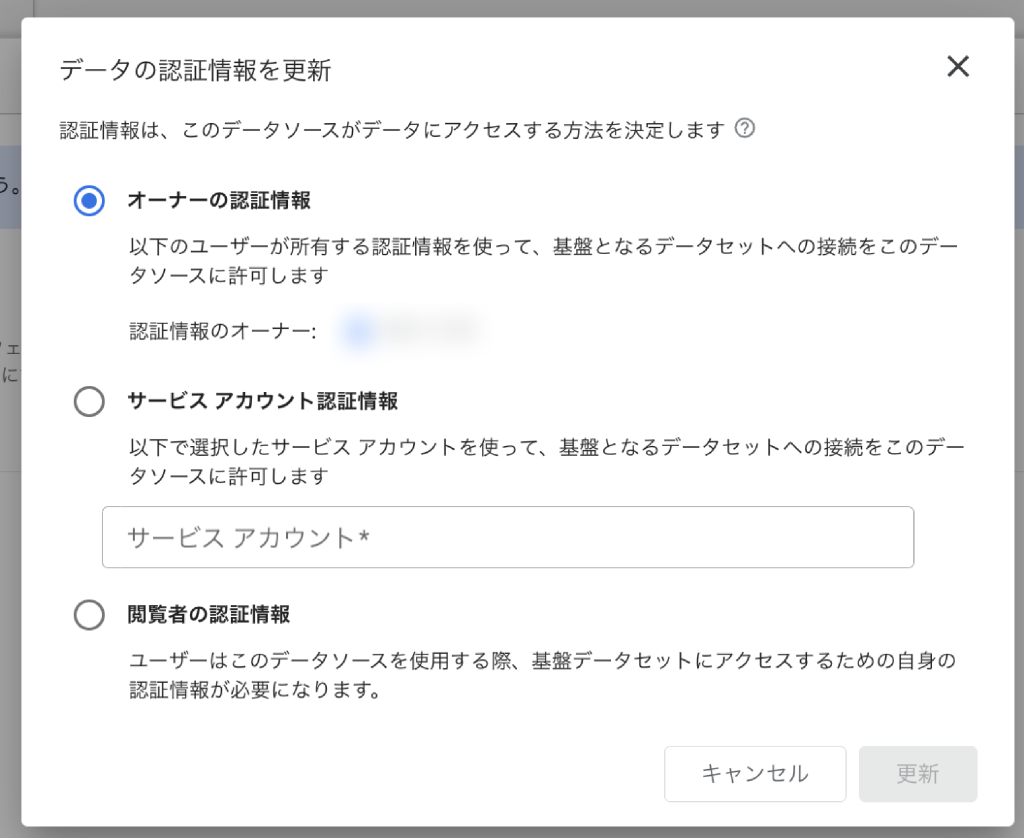
①オーナーの認証情報
データセットへのアクセスにオーナー自身の認証情報が使用されます。レポートの閲覧者が基になるデータセットへのアクセス権を持っていなくても、レポートを共有し表示させることが可能です。
②サービスアカウント認証情報
ユーザー自身のアカウントではなく、サービスアカウントと呼ばれる特別なタイプのGoogleアカウントを利用して、データにアクセスし認証を行います。自動処理やシステム間連携において有効な方法です。
③閲覧者の認証情報
この設定では、レポートを閲覧するユーザー自身が、データソースにアクセスするための権限を持っている必要があります。個人のアクセス権に基づいてデータの表示可否が決まります。
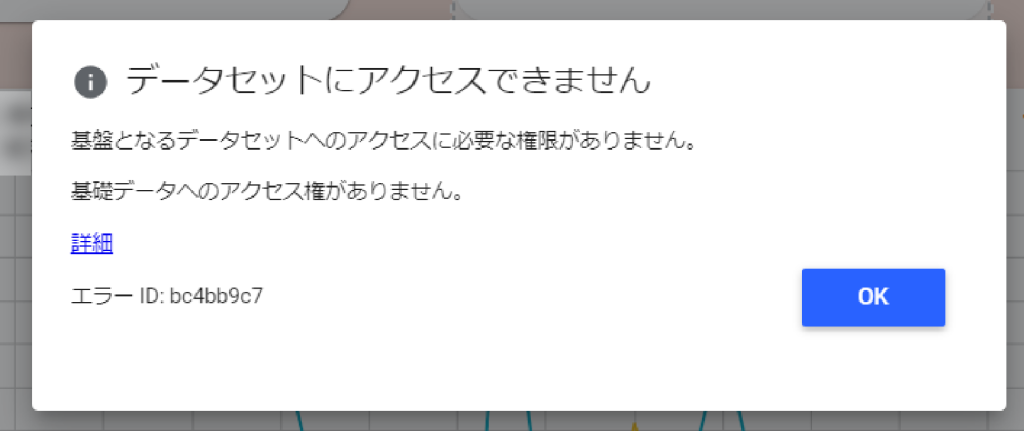
💡『データセットにアクセスできません』というエラーが表示された場合は、閲覧者にアクセス権限がない可能性があります。その際は、オーナーに連絡して認証情報の変更を依頼しましょう。
「追加」をクリック
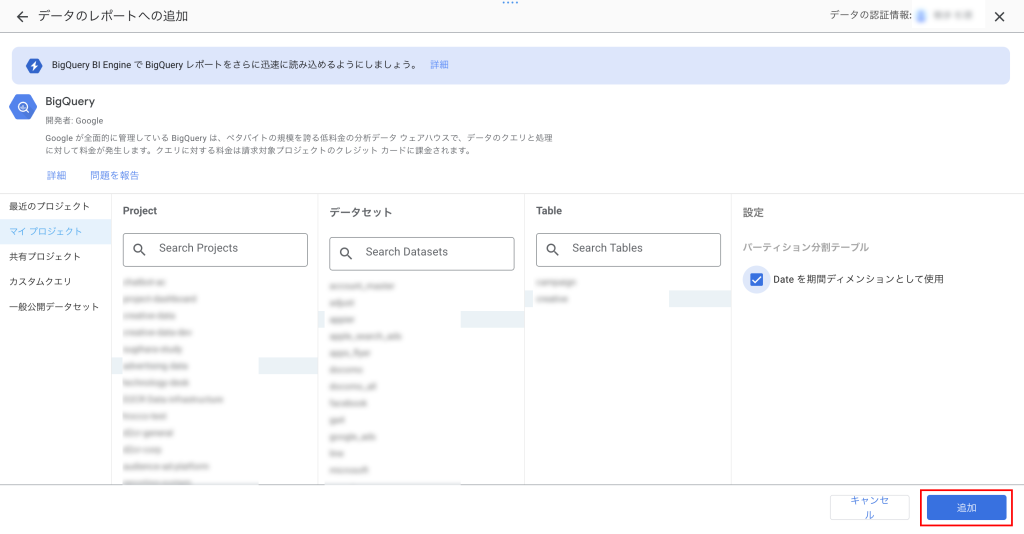
これでデータの追加は完了です。
ヘッダーの「グラフを追加」から、先ほど追加したデータソースを選択してグラフを描画できます。
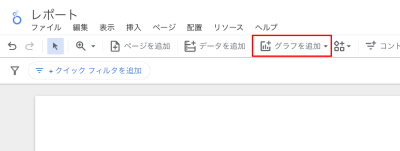
またヘッダーの「リソース」>「追加済みのデータソースの管理」からデータソース一覧を確認できます。
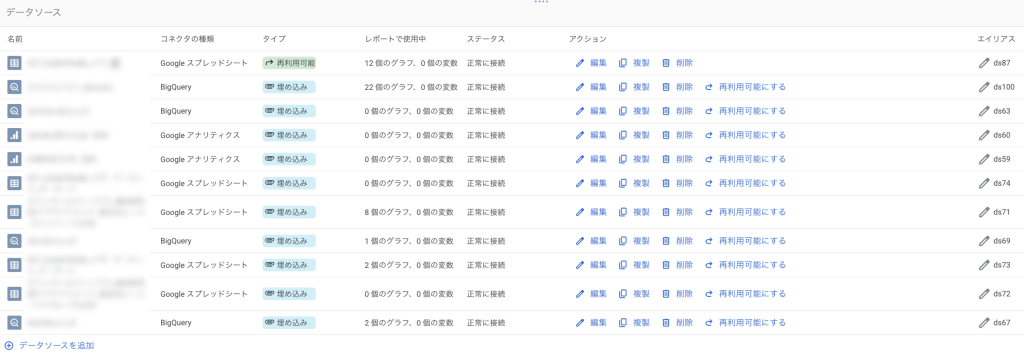
「タイプ」に表示される「埋め込み」は、特定のレポートに紐付けられるデータソースです。他のレポートで再利用できず、常に元のレポート内に埋め込まれた状態で使われます。そのため、更新頻度や認証情報は個別に設定できず、接続元の設定を引き継ぎます。
一方、「再利用可能」は、他のユーザーと共有したり、自身の別のレポートでも同じ接続設定を再利用できるデータソースです。共有することで接続の一貫性が保たれ、複数のレポートで効率よく活用できます。
作成する際には、そのレポート専用のデータ接続や設定を使いたい場合、または他のレポートと共有する必要がない場合は、「埋め込み」データソースを選ぶのがおすすめです。逆に複数のレポートで同じデータ接続や設定を再利用したい場合や、他のユーザーとデータソースを共有して共同作業を行いたい場合は、「再利用可能」なデータソースを選ぶと良いでしょう。
データの結合手順
Looker Studioでは、「統合」機能を使うことで、複数のデータソースを結合し、一つのデータソースのようにまとめて可視化することができます。
例えば、異なるBigQueryテーブルに保存された広告アカウント情報と予算の詳細情報を結合し、1つの表にまとめて表示することで、全体像の把握や分析がより効率的に行えます。
ヘッダー「リソース」>「結合を管理」
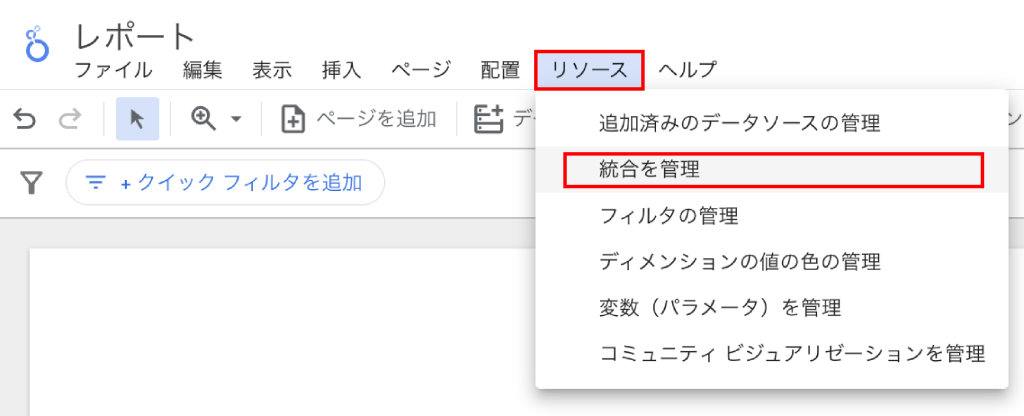
「結合を追加」をクリック
テーブルの指定
結合したいデータソースを選択して追加します。結合できるデータソースは最大5つまでです。1対多の関係がある場合は、「1」にあたるテーブルを端に配置するのが推奨されます。また、リレーションのあるテーブル同士は隣接させて配置すると、構造が視覚的にわかりやすくなります。
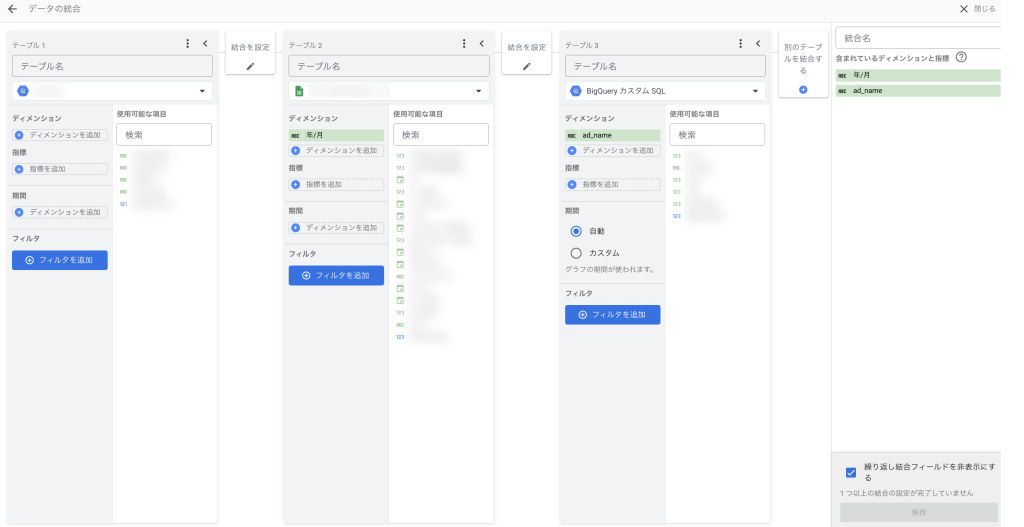
フィールドの指定
各テーブルで、使用するフィールドを「ディメンション」と「指標」に分けて指定します。
「ディメンションを追加」から選択、または右の使用可能な項目からドラッグ&ドロップで移動させます。
ディメンションは、日付、アカウント名、カテゴリなど、一般的に数値以外のフィールドで、データを集計する際の「軸」となる項目です。
一方、指標はクリック数や売上高など、集計や計算の対象となる数値データを指します。
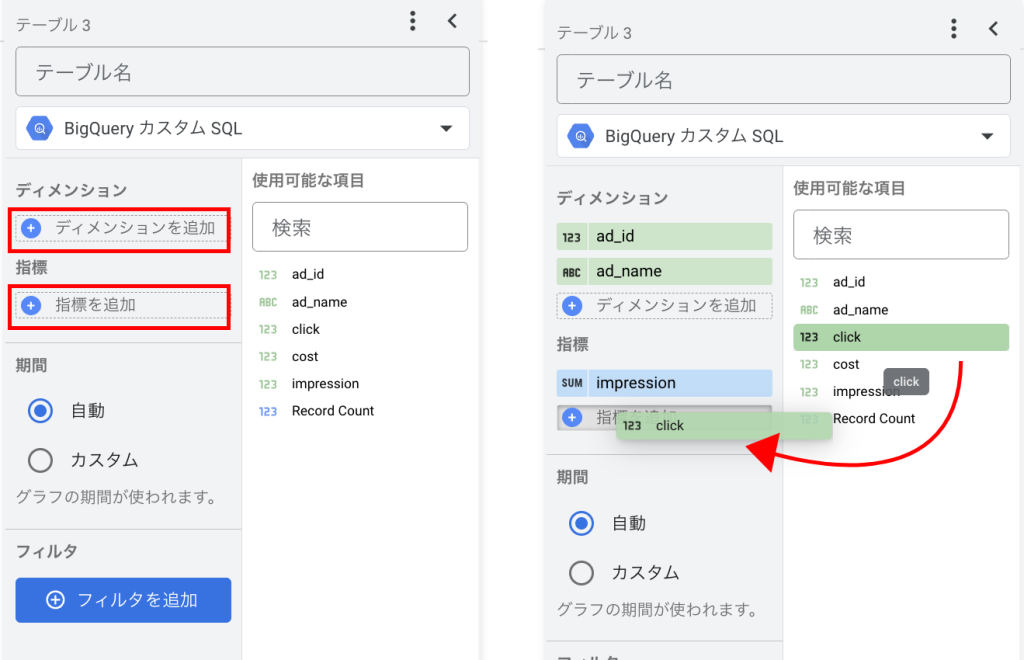
💡結合データを作成する際、一つのテーブルに設定できるディメンションは最大10個、指標は最大20個までです。これらの上限を超える場合は、結合ではなくデータベース側での処理を検討することをお勧めします。また、同じテーブルを内部結合することで、異なるディメンションを表示させることも可能ですが、その際は結合キーやデータの重複に注意が必要です。
テーブルを結合
結合するテーブルの「結合を設定」を選択します
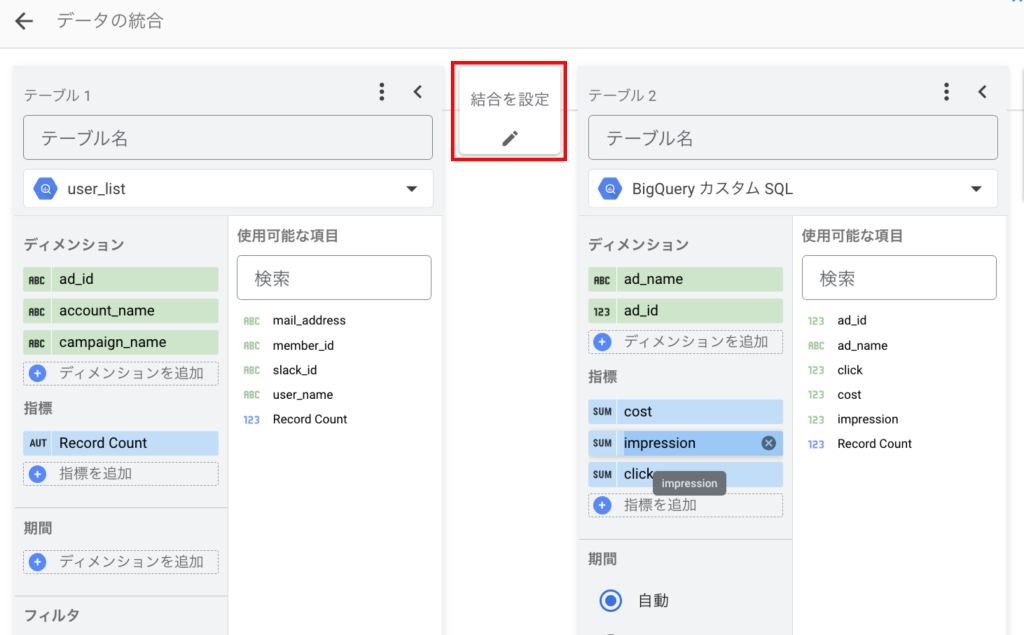
右側のテーブルと一致するフィールドを左側のテーブルから1つ以上設定します。
データの内容が一致していれば、すべてのテーブルで同じフィールドである必要はなく、同じ名前である必要もありません。
またフィールド名を任意のテキストに変更したり、計算式など新規のフィールドを作成したりすることもできます。
💡結合キーは、名前が異なっていてもデータ型が一致している必要があります。たとえば、「2025年5月」と「2025-05-01」のように形式が異なる場合、そのままでは結合できません。結合前に、CAST や FORMAT_DATE 関数を使って形式やフォーマットを揃えましょう。
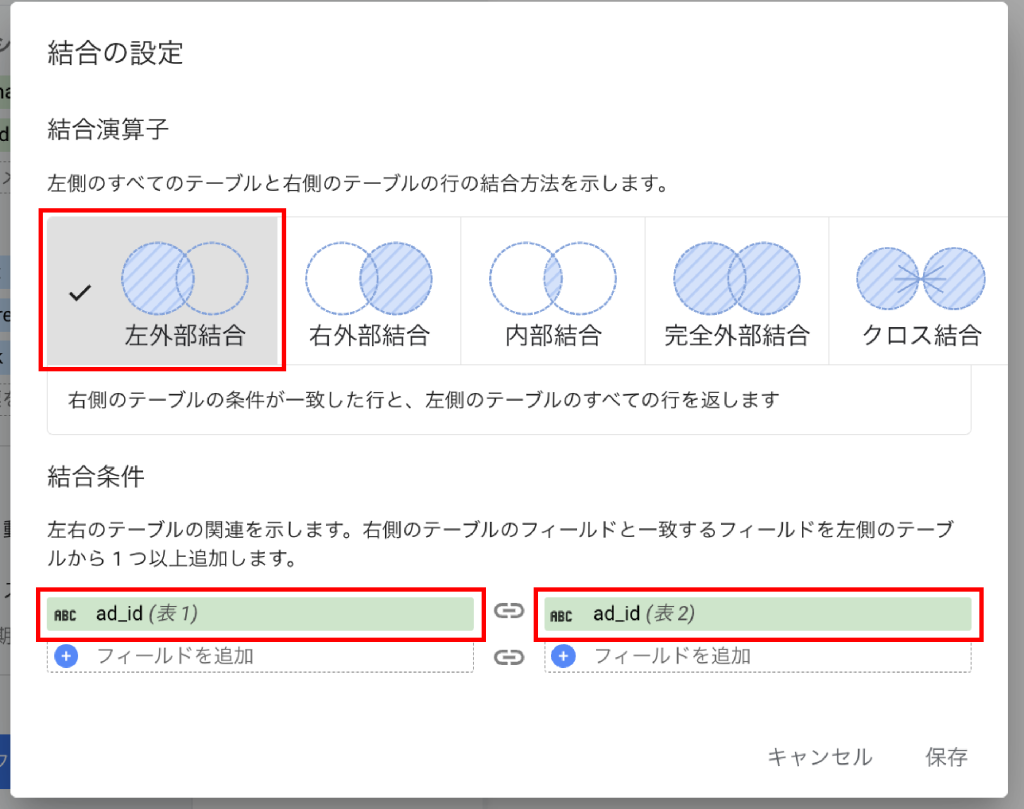
結合演算子は、結合するテーブル間で一致する行や一致しない行をどのように扱うかを定義します。Looker Studioで利用できる主な結合演算子は以下の通りです。
左外部結合(LEFT OUTER JOIN)
左側のテーブルのすべての行と、右側のテーブルで結合条件が一致する行を返します。一致する行が右側のテーブルに存在しない場合は、右側のカラムに NULL が表示されます。左側のテーブルを主とし、右側のテーブルから追加情報を取得したい場合に利用します。
右外部結合(RIGHT OUTER JOIN)
右側のテーブルのすべての行と、左側のテーブルで結合条件が一致する行を返します。ただし、右外部結合は左外部結合で左右のテーブルを入れ替えることで代用できるため、実際には左外部結合がよく使われます。
内部結合(INNER JOIN)
左右両方のテーブルで、結合条件が一致する行のみを返します。両方のテーブルに共通するデータのみが必要な場合に使用します。
完全外部結合(FULL OUTER JOIN)
左右両方のテーブルに存在するすべての行を返します。結合条件が一致しない場合、それぞれのテーブルの対応しないフィールドには NULL が表示されます。両方のテーブルの情報を統合したい場合に使用します。
クロス結合(CROSS JOIN)
左右両方のテーブルに存在するすべての行の組み合わせを返します。組み合わせの数が多くなるため、使用には注意が必要です。
オプションの設定
必要に応じて以下のオプションを設定します。
①繰り返し結合フィールドを非表示
結合条件に使用された重複フィールドを除外するかを設定できます。キーフィールドは1つだけ表示されるため、可読性を高める目的で基本的にオンにするのが推奨されます。一方で元のテーブルで異なる意味を持つ場合は、オフにすることで両方のフィールドを保持できます。
②フィルタ
ひとつ以上のテーブルに期間やフィルタを適用することで統合データの範囲を制限できます。
③統合名
統合されたデータに任意の名前をつけることができます。
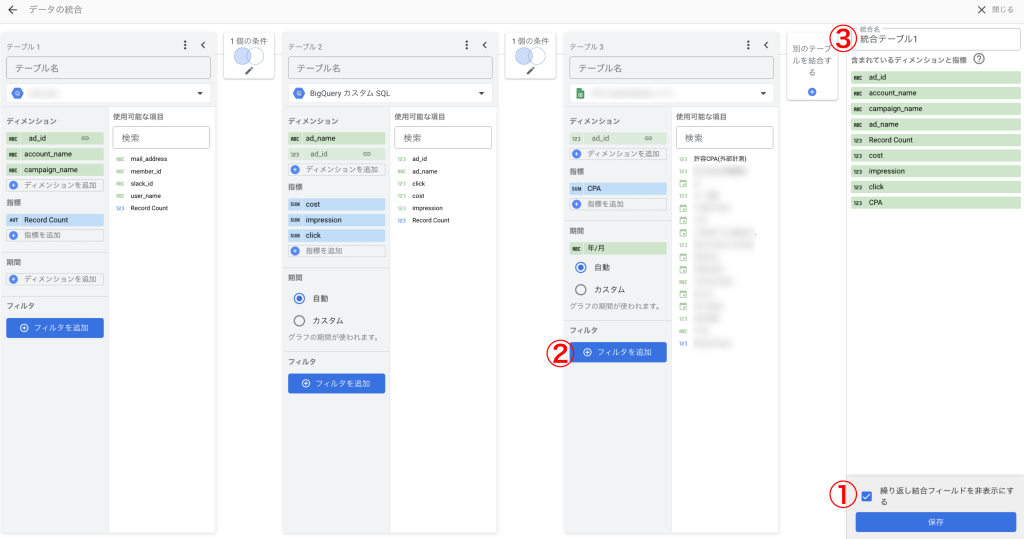
「保存」をクリック
これでデータの統合は完了です。
データソースと同様に、ヘッダーの「グラフを追加」から、先ほど追加した混合データを選択してグラフを描画できます。
まとめ
Looker Studioでデータの接続や結合を活用することで、複数のデータソースをより包括的に分析でき、カスタマイズ性の高いダッシュボードの作成が可能になります。
目的やデータ構造に応じて、適切な接続と統合を選び、データの可視化を最大限に活用しましょう。
今回はLooker Studioの使い方についてご紹介しましたが、実際の業務では、TROCCOを活用したデータの自動集約・加工と組み合わせることで、より効率的で再現性の高いダッシュボード構築が可能になります。TROCCOについては、TROCCO(トロッコ)とは?主要機能・特徴・料金・類似サービスとの違いを解説で、主要機能や導入支援についてご紹介していますので、あわせてご覧ください。
またD2C RではTROCCOによるデータ処理基盤の整備から、Looker Studioを用いた可視化・レポーティングの設計・構築まで一貫した支援を行っています。
詳しくはこちらよりお気軽にお問い合わせください。
この記事が参考になった方は「いいね」やシェアをお願いします!
▼データマーケティングの教科書 下
初心者の方から、より詳しくなりたいという方へ。
本書ではデータマーケティングの基礎から学び、データを通じて顧客の行動や感情を理解し、
より確かな意思決定を目指します。
編集者
エンジニアチーム
編集者
エンジニアチーム
GASやLooker Studio、TROCCOなどのツールを活用した、業務効率化やデータ活用のノウハウをわかりやすく発信しています!




