TROCCO #02|データマート定義の設定方法とSQL活用例

▼データマーケティングの教科書 下

初心者の方から、より詳しくなりたいという方へ。
本書ではデータマーケティングの基礎から学び、データを通じて顧客の行動や感情を理解し、
より確かな意思決定を目指します。
みなさん、こんにちは!
前回の記事では、TROCCOを使ったデータ転送設定の基本的な手順から、スケジュール設定・通知設定などの実用的なオプション機能までをご紹介しました。
今回はさらに一歩進んで、TROCCOの「データマート機能」に焦点を当てます。
この機能を活用することで、転送したデータを目的別に集約・加工し、分析に最適な構造で保管することが可能になります。
「必要なデータだけを整理して、すぐに使える形で保存しておきたい」という、現場でよくある悩みもこれでスッキリ解消できるはずです。
本記事では、初めてデータマートを使う方にもわかりやすく、実際の設定画面を交えてステップごとに丁寧に解説していきます。
BigQueryなどの活用を見据えたスマートなデータ整備の第一歩として、ぜひ参考にしてください!
データマートとは
TROCCOの「データマート」は、複数の転送ジョブやデータソースを組み合わせて、分析に適した形式へと加工・集約する中間テーブルのような役割を持つ機能です。
「データ転送」では、各ソースから取得したデータをそのままBigQueryなどに保存していました。しかし「データマート」では、複数の転送結果を横断的に扱い、SQLによる整形やフィルタ処理を加えたうえで、統一された形式で再構築することが可能です。
たとえば、Google広告とYahoo!広告のデータをそれぞれ別の転送ジョブで取得している場合、それぞれの形式が異なることが一般的です。こうしたデータをデータマートに取り込んで、SQLで媒体ごとのフォーマットを統一すれば、すぐに分析やBIツールでの可視化に使えるデータが出来上がります。
データマート作成手順
左メニューから「データマート」を選び「新規作成」から作成したいサービスを選択してください。
- Google BigQuery
- Snowflake
- Amazon Redshift
- Azure Synapse Analytics
今回はBigQueryを選択します。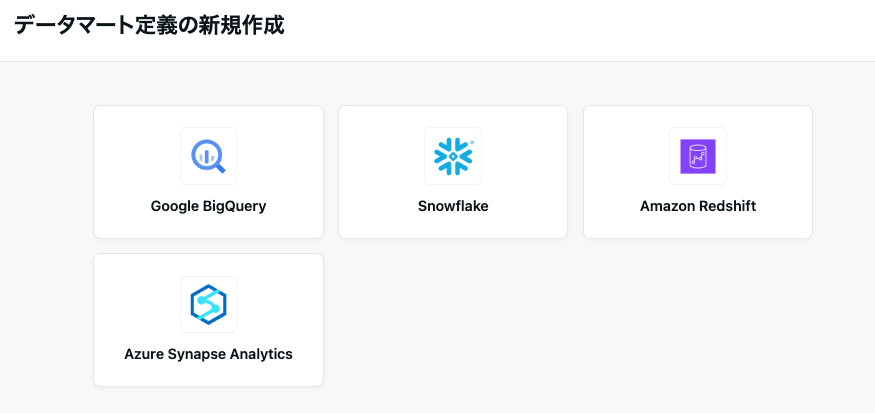
データマート定義の設定
画面に従い、各設定項目を入力します。
概要設定
【データマート定義名】作成するデータマート定義の名前を入力します
例)Google Ads:キャンペーン実績_日次集計

基本設定
【Google Ads接続情報】接続情報を追加するか、既存の接続情報を選択してください
【カスタム変数】カスタム変数とは、設定項目に埋め込むことができる動的な変数であり、ジョブの実行時にその値が自動的に展開されます。
たとえば、変数名に $today$ を指定すると、SQL文やテーブル名、データ取得期間の条件などに埋め込んで使用することができます。
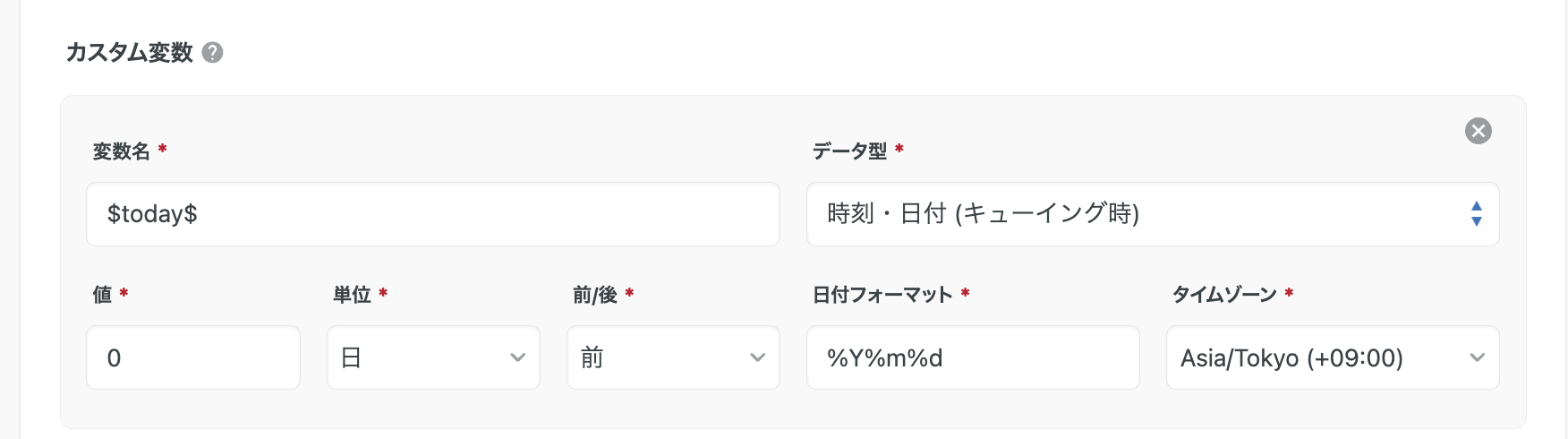
💡データ型の時刻・日付 (キューイング時) と時刻・日付 (実行時) は、カスタム変数に値を展開する際の基準日時に違いがあります。
時刻・日付 (実行時) :該当ジョブの開始日時が基準。(実際にそのジョブが動き出した時間が基準)
時刻・日付 (キューイング時) :該当ジョブの実行がトリガーされた日時が基準。ワークフローがリトライして再実行されても、基準は 最初にトリガーされた時刻のまま。
スケジュール設定を用いてジョブを実行する場合は 「時刻・日付(キューイング時)」を使うことが推奨されています。ジョブが失敗して翌日以降に再実行されたとしても、カスタム変数には 最初に実行を予定していた日時を基準に値が展開されるため、処理の基準日がぶれずに済むためです。
クエリ設定
【クエリ実行モード】「データ転送モード」と「自由記述モード」の2つのSQL記述方式を選択することができます。
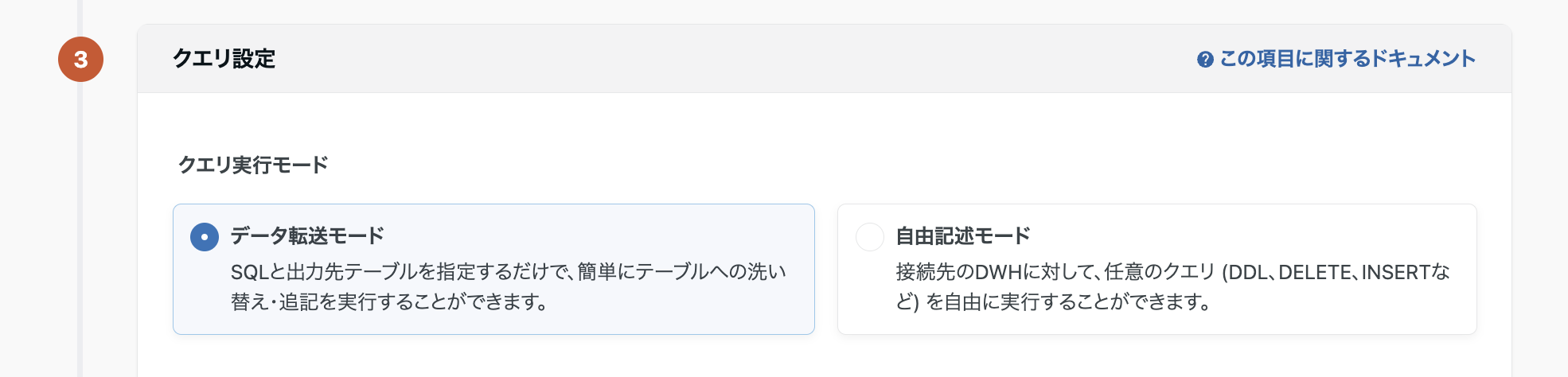
データ転送モードとは、TROCCOであらかじめ設定されている「転送ジョブ」から出力されたテーブルを選択し、そのデータをもとにSQLを組み立ててデータマートを作成するモードです。GUI上で対象テーブルを選ぶだけで、テーブル名やパスなどを自分で記述する必要がないため、初めてデータマートを作成する方でも扱いやすいのが特徴です。
このモードは、TROCCO内でデータ転送がすでに設定されており、その出力結果をベースに加工処理を行いたい場合に適しています。また、転送ジョブとデータマートとの依存関係が自動で管理されるため、データの整合性が保ちやすく、ワークフロー内で定期的にデータマートを更新したいケースにも向いています。
データマートの出力先には、加工結果を保存するためのデータセットとテーブル名を指定します。
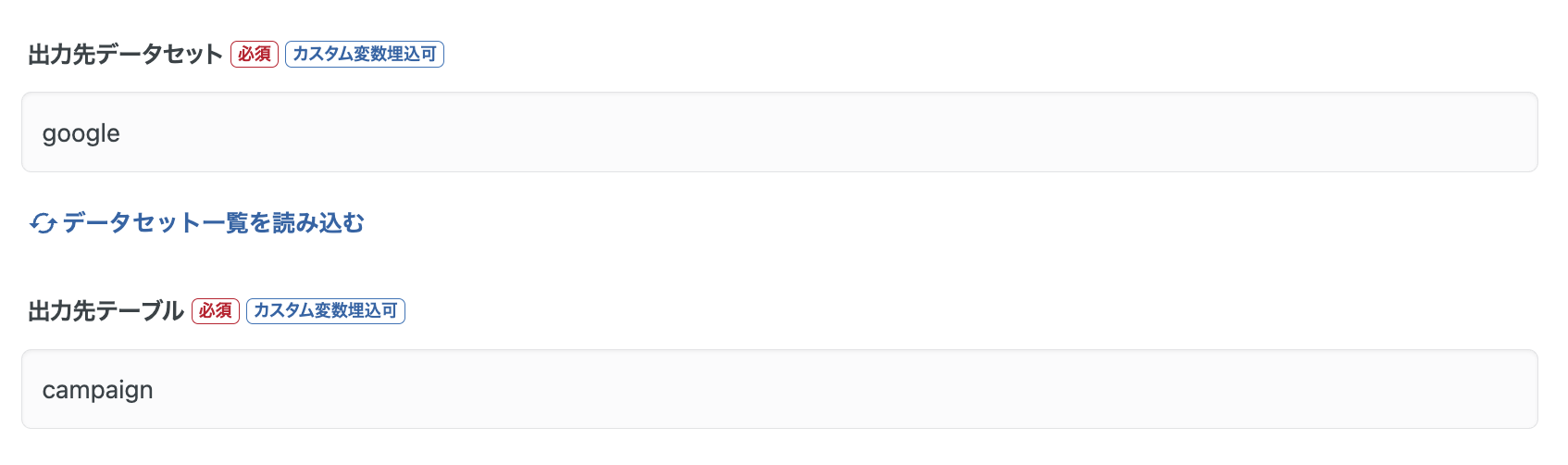
自由記述モードは、任意のSQLを自由に記述できるモードです。
TROCCOで管理していないテーブルや、外部で管理されているBigQueryテーブルなども対象にできるため、より柔軟で複雑なSQL処理が可能になります。
TROCCO外のデータやカスタムビューを組み合わせたい場合、また複雑な前処理やロジックをSQLで記述したい場合には、自由記述モードを選択するのが適しています。
【クエリ】SQLを用いて、複数のデータソースから集めた情報を目的に応じて再構成・集計し、新たな「分析用テーブル(マート)」として出力できます。
このSQLは、接続先のデータウェアハウスの構文ルールに従って記述します。以下はクエリの活用例です。
| フィールド名 | 名前 |
| project_id | プロジェクト名 |
| dataset_id | データセット名 |
| google_ads_campaign | テーブル名(例:Google広告のデータテーブル) |
| yahoo_ads_campaign | テーブル名(例:Yahoo!広告のデータテーブル) |
| conversion | テーブル名(例:CVデータテーブル) |
| update | テーブル名(例:最新データテーブル) |
①異なる広告媒体のデータを共通フォーマットに統一
媒体ごとに異なるデータ構造を、BIツールで一貫して扱いたい時に、データマートで事前に整形・統合することができます。
SELECT
'google_ads' AS media,
campaign_name,
segments_date,
metrics_impressions,
metrics_cost_micros
FROM
`project_id.dataset_id.google_ads_campaign`
UNION ALL
SELECT
'yahoo_ads' AS media,
CAMPAIGN_NAME,
DAY,
IMPS,
COST
FROM
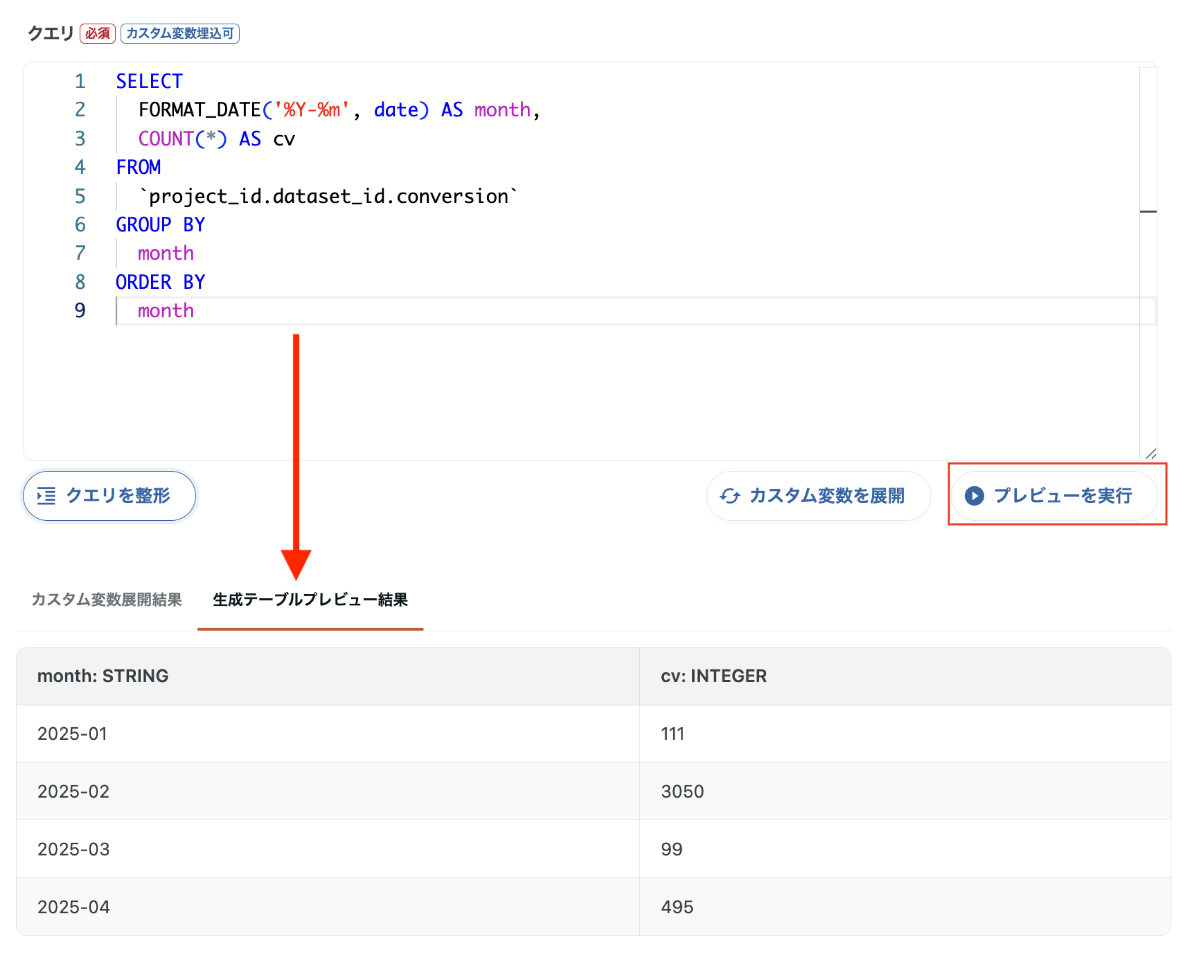
`project_id.dataset_id.yahoo_ads_campaign`②日別のCV数を月次に集計
日次で取得したデータを月次で集計することができます。
SELECT
FORMAT_DATE('%Y-%m', date) AS month,
COUNT(*) AS cv
FROM
`project_id.dataset_id.conversion`
GROUP BY
month
ORDER BY
month
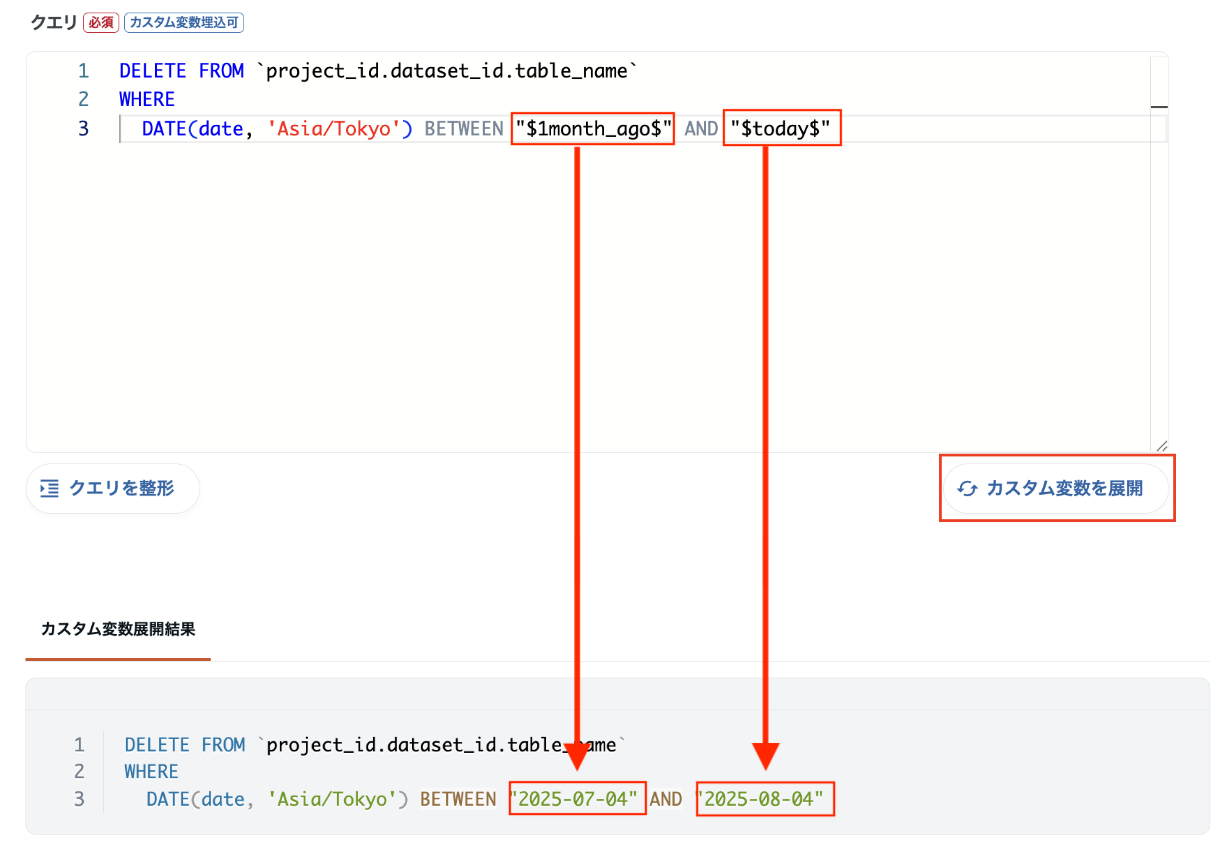
③1ヶ月分のデータを削除
1ヶ月分のデータを再処理して上書きしたい場合、先に対象期間のデータを削除し、その範囲だけ再出力することで、部分更新型のバッチ処理が可能になります。
削除処理を行うには、自由記述モードで DELETE を使用してください。
DELETE FROM `project_id.dataset_id.update`
WHERE
DATE(date, 'Asia/Tokyo') BETWEEN "$1month_ago$" AND "$today$"【カスタム変数を展開】TROCCOのデータマート定義で「カスタム変数を展開」すると、SQL内の変数(例:$today$)が実行時に自動で置き換えられます。
【プレビューを実行】データマート定義のSQLに対して一部データを使ってクエリを実行し、出力されるデータのプレビューを画面上で確認できます。出力先テーブルには書き込まれないため、SQLの文法ミスや参照テーブルの誤りなどを本番実行前に安全にチェックできます。
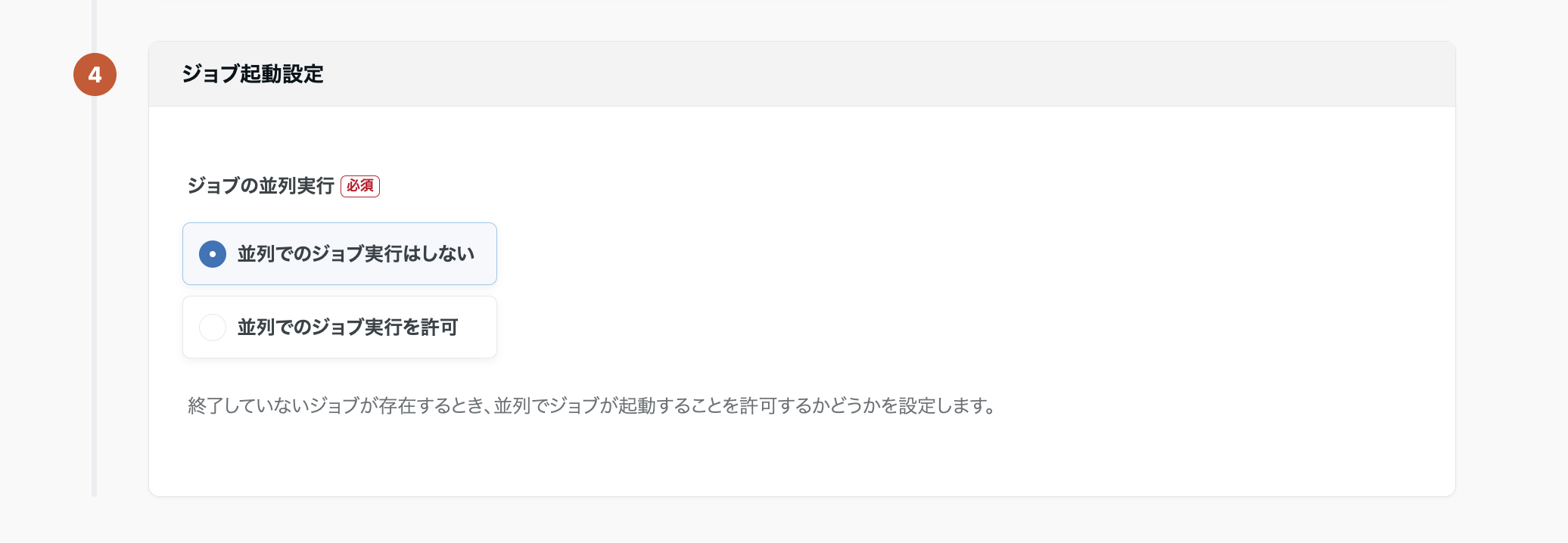
ジョブ起動設定
【ジョブの並行実行】並行でジョブ実行を許可した場合、複数のデータマート定義を同時に実行することができます。
実行時間の短縮が期待できる一方で、ある定義の出力を次の定義が参照するような依存関係がある場合は、「並行でのジョブ実行はしない」を選択しましょう。
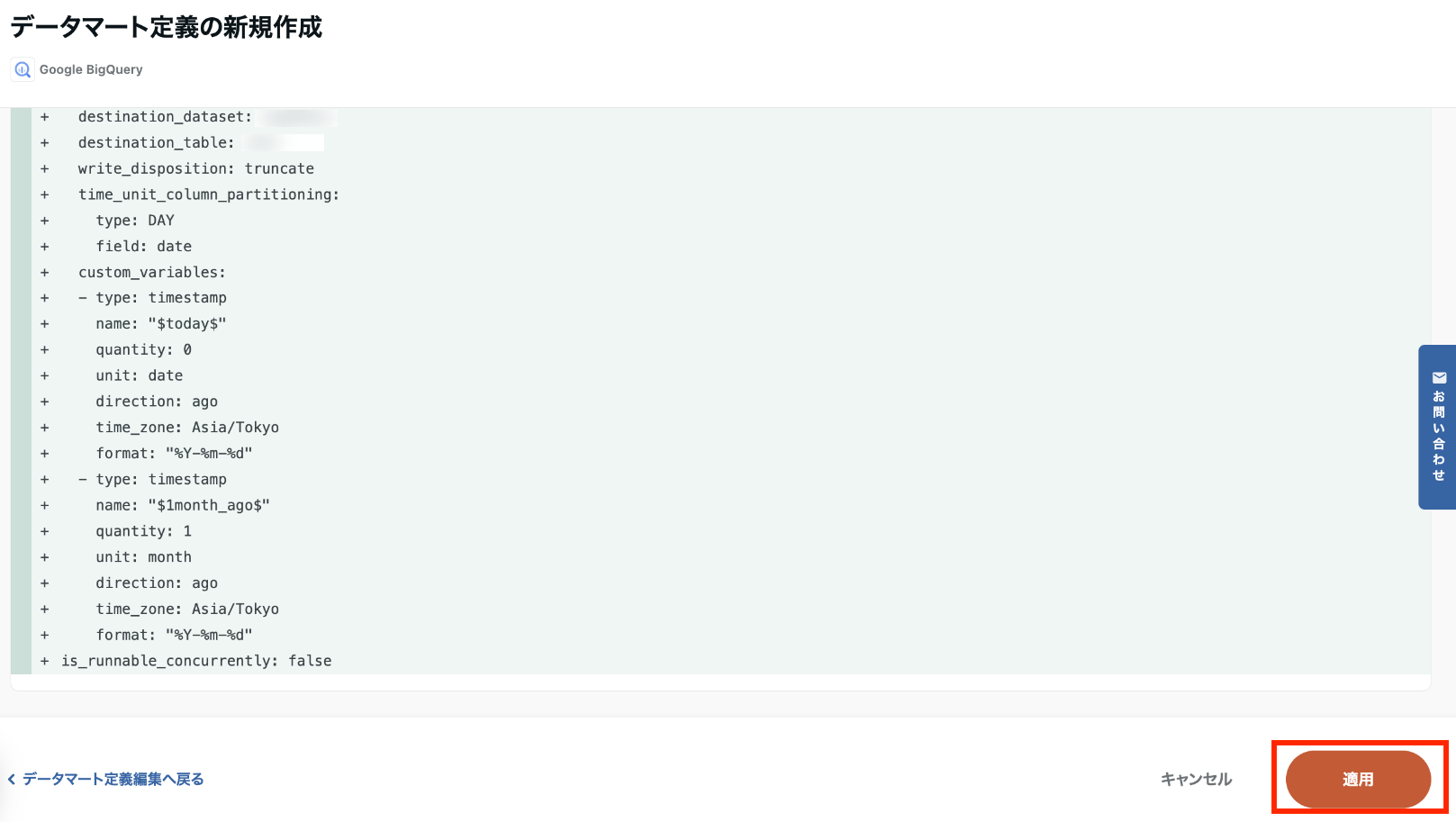
データマート設定を記入後、「確認画面へ」をクリックします。
確認画面へ遷移後、内容に問題なければ「適用」をクリックします。
データマート定義の追加設定
ラベル
ラベルを設定し管理することができます。転送設定を検索する時にも便利です。

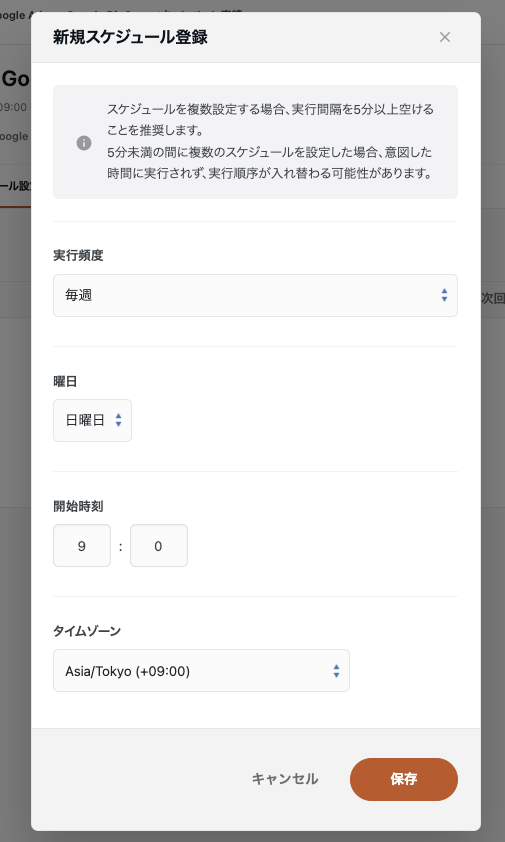
実行スケジュール
転送ジョブの自動実行スケジュールを設定できます。
例えば「毎週日曜日9時に自動でジョブを実行する」ということが可能になります。
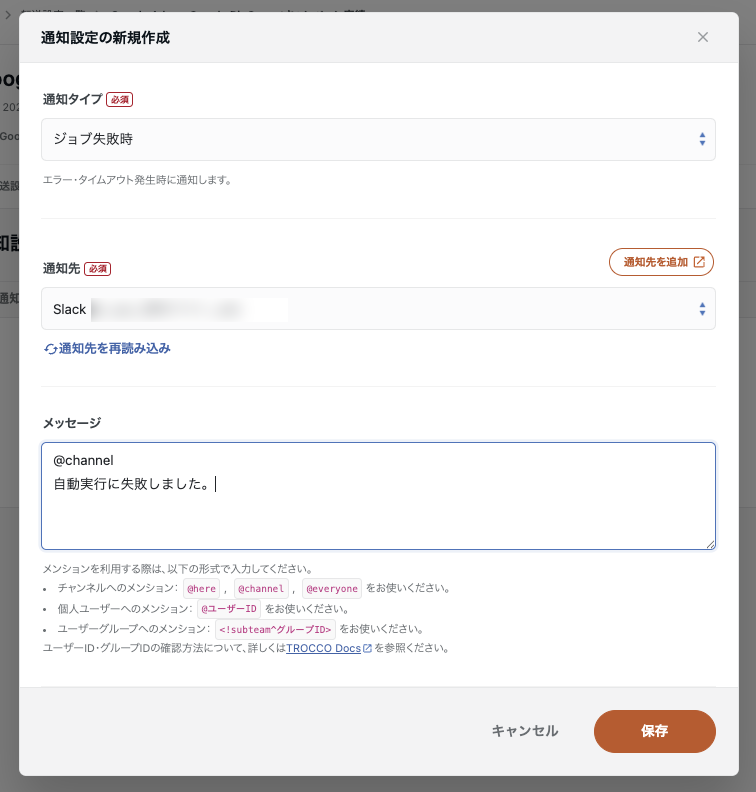
通知設定
ジョブ終了時やジョブ失敗時、実行経過条件、レコード数条件に応じて通知を設定できます。
通知はSlackやEmailで受け取ることが可能です。通知先は、新しく作成するか、既存の通知先から選択してください。
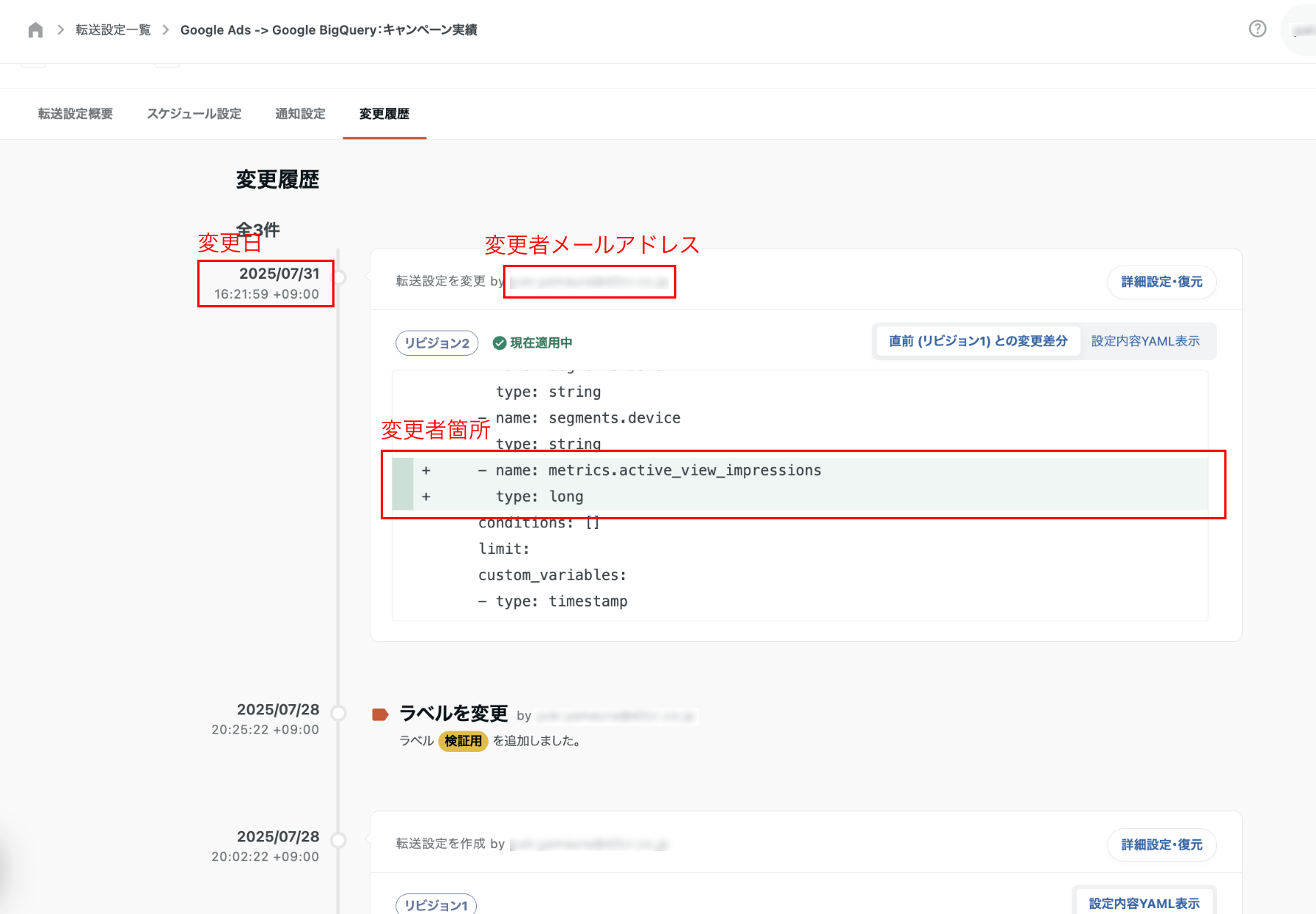
変更履歴
転送設定の変更履歴では、いつ、誰が、どの部分を編集したのかを確認することができます。
リビジョンの「詳細・復元」からは設定を復元することも可能です。
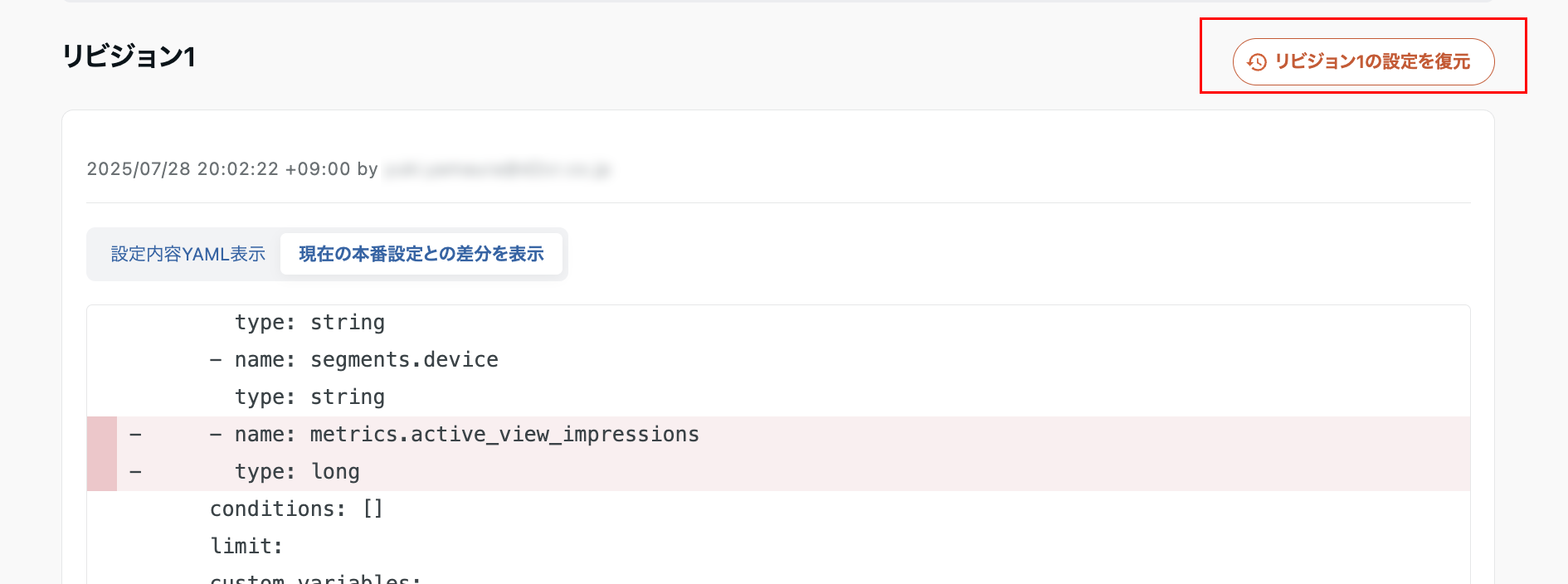
💡リビジョンを復元する際、スケジュール・通知設定などは復元対象になりません。スケジュールや通知に影響がないか確認してから復元するよう注意しましょう。
まとめ
本記事では、TROCCOにおけるデータマート機能の概要から、モードの違いやユースケース、SQLの記述例までを解説しました。自由度の高いSQL記述とGUIベースの運用管理を組み合わせることで、柔軟かつ安定したデータ活用が期待できます。データ基盤の構築やレポーティングの効率化に、ぜひ活用してみてください!
実際の業務においても、TROCCOを活用したデータの自動集約・加工と組み合わせることで、より効率的で再現性の高いダッシュボード構築が可能になります。他にもTROCCOについては、TROCCO(トロッコ)とは?主要機能・特徴・料金・類似サービスとの違いを解説で、主要機能や導入支援についてご紹介していますので、あわせてご覧ください。
またD2C RではTROCCOによるデータ処理基盤の整備から、Looker Studioを用いた可視化・レポーティングの設計・構築まで一貫した支援を行っています。
詳しくはこちらよりお気軽にお問い合わせください。
この記事が参考になった方は「いいね」やシェアをお願いします!
▼データマーケティングの教科書 下
初心者の方から、より詳しくなりたいという方へ。
本書ではデータマーケティングの基礎から学び、データを通じて顧客の行動や感情を理解し、
より確かな意思決定を目指します。
編集者
エンジニアチーム
編集者
エンジニアチーム
GASやLooker Studio、TROCCOなどのツールを活用した、業務効率化やデータ活用のノウハウをわかりやすく発信しています!




